
决策树性能
决策树性能
提问于 2020-04-22 08:35:13
如果我们不给任何约束,如max_depth,minimum number of samples for nodes,决策树总能给0训练错误吗?还是取决于数据集?显示的数据集呢?
编辑-它有可能有一个分裂,从而导致的准确性低于父节点,对吗?根据决策树理论,即使几次分割后的最终结果可以很好,也应该停止在那里进行分割!我说的对吗?

回答 1
Stack Overflow用户
回答已采纳
发布于 2020-04-22 09:34:50
决策树将始终找到提高准确性/得分的分割。
例如,我在与您的数据相似的数据上构建了一个决策树:
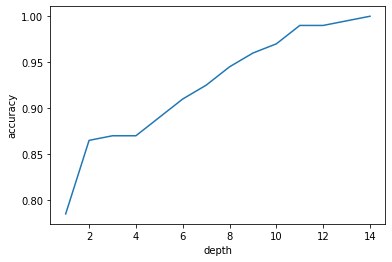
一个决策树可以达到100%的准确性,在任何数据集,没有两个样本具有相同的特征值,但不同的标签。
这就是为什么决策树往往过于适合的原因之一,特别是在许多特性上或在有许多选项的分类数据上。
实际上,有时,如果拆分所产生的改进不够高,我们就会防止节点中的分裂。这是有问题的,因为一些关系,比如y=x_1 xor x_2,不能用树来表示。
因此,通常情况下,树不会停下来,因为他不能改进训练数据的模型。不能百分之百准确地看到树木的原因是,我们使用一些技术来减少过度拟合,例如:
- 树木修剪就像这个比较新的例子.这基本上意味着您构建了整个树,但随后返回并修剪那些对模型性能贡献不够的节点。
- 使用一个比率,而不是对分裂的增益。基本上,这是一种表达这样一个事实的方法:我们期望从50%-50%的分裂中得到的改善要比10%-90%的分裂少一些。
- 设置超参数(如
max_depth和min_samples_leaf),以防止树过度分裂。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61360695
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号