
熊猫:填充细胞向下算法
在下面的示例中,我需要填充“父”列,如下所示:除了行0和行7之外,所有列值都是CISCO (应该留空)。
请注意,'CISCO‘在'CISCO System’下面的单元格中,在CISCOs的fact..all中的'CISCO Systems‘下面的单元格中,所以我需要将所有具有相同起始单元的单元格分组为一个实体,并用起始单元(CISCO)标记父单元(CISCO)。
我们有同一个供应商的多个名称,所以我试图将所有这些子“CISCOs”映射到父“CISCO”
请注意,我有100,000行,因此该算法必须在不需要人工干预的情况下自动完成(也就是说,不能简单地通过硬编码父母= 'CISCO')
df = pd.DataFrame(['MICROSOFT','CISCO', 'CISCO System', 'CISCO Systems', 'CISCO Systems CANADA', 'CISCO Systems CANADA Corporation', 'CISCO Systems CANADA Corporation Limited', 'IBM'], columns=['Child']) #,[]], columns=['Child', 'Parent'])
df['Parent'] = ''
df我希望有一个优雅的解决方案,最好不需要循环。非常感谢你的帮助!
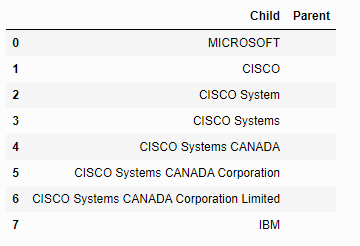
所需产出:
回答 3
Stack Overflow用户
发布于 2020-05-02 07:04:33
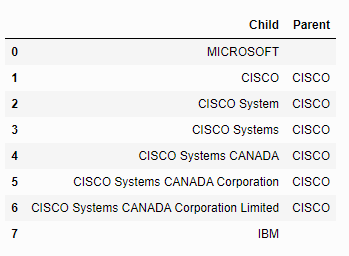
作为将来的参考,我已经提出了一个非常优雅和简单的解决方案,它的用词与我想要的完全一样:
import pandas as pd
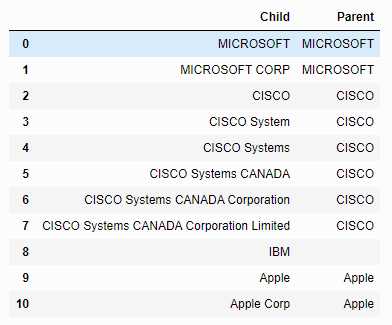
df = pd.DataFrame(['MICROSOFT', 'MICROSOFT CORP','CISCO', 'CISCO System', 'CISCO Systems', 'CISCO Systems CANADA', 'CISCO Systems CANADA Corporation', 'CISCO Systems CANADA Corporation Limited', 'IBM', 'Apple','Apple Corp'], columns=['Child'])
df['Parent'] = ''
c, p = df['Child'], df['Parent']
for y in range (1, df.shape[0]):
if c.iat[y-1] in c.iat[y]: p.iat[y] = np.nan #identify children
if str(p.iat[y]) == 'nan' and p.iat[y-1] == '' : p.iat[y-1] = c.iat[y-1] #identify parent
df['Parent'] = df['Parent'].ffill(axis = 0) #fill children
display(df)输出:
Stack Overflow用户
发布于 2020-04-22 09:14:46
这是卷曲的。我又一次尝试;
数据
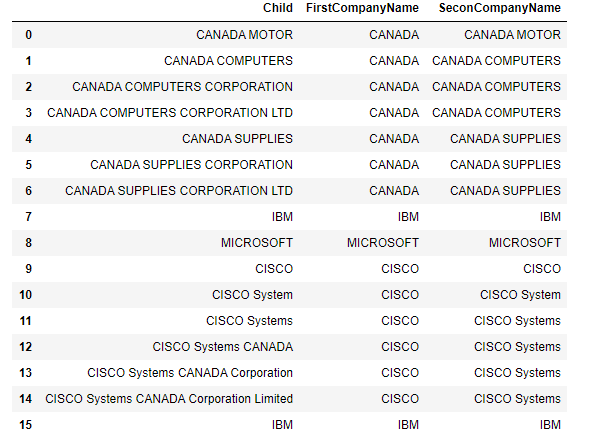
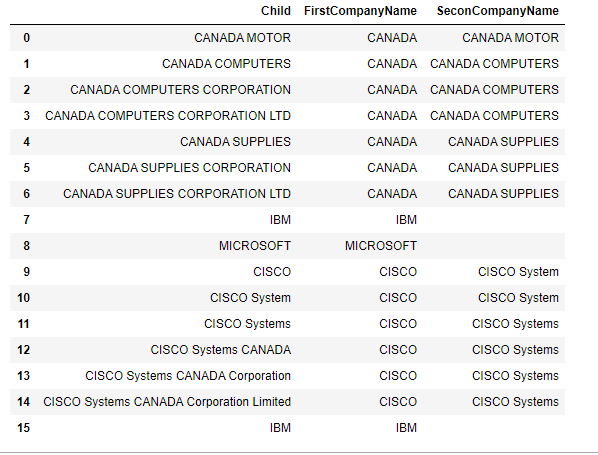
df = pd.DataFrame({'Child':['CANADA MOTOR','CANADA COMPUTERS', 'CANADA COMPUTERS CORPORATION', 'CANADA COMPUTERS CORPORATION LTD', 'CANADA SUPPLIES', 'CANADA SUPPLIES CORPORATION', 'CANADA SUPPLIES CORPORATION LTD', 'IBM','MICROSOFT','CISCO', 'CISCO System', 'CISCO Systems', 'CISCO Systems CANADA', 'CISCO Systems CANADA Corporation', 'CISCO Systems CANADA Corporation Limited', 'IBM']})将每个孩子的名字提取到FirstCompanyName中
df['FirstCompanyName']=df.Child.str.extract('(^\w+)')提取每个子名称到df2中的第一个和第二个名称,将那些没有第二个名称的名字删除,并将列重命名为Child和SeconCompanyName
df2=df.Child.str.extract('(^((?:\S+\s+){1}\S+).*)', expand=True).dropna()
df2.columns=['Child','SeconCompanyName']合并两个数据文件,替换任何NaNs并删除不需要的列
df3= pd.merge(df, df2, left_index=True, right_index=True, how='left',suffixes=('', '_New'))
#df3.fillna('', inplace=True)#
df3.drop(columns=['Child_New'], inplace=True)
df3掩码,其中SeconCompanyName为空
m=df3.SeconCompanyName.isna()在掩码仍在时用SeconCompanyName替换为FirstCompanyName
df3.loc[m,'SeconCompanyName']=df3.loc[m,'FirstCompanyName']
df3结果1
如果你不喜欢上面的内容,跳过面具,然后做下面的事情;
df3['SeconCompanyName']=np.where(df3.SeconCompanyName.isna(), df3.shift(-1).SeconCompanyName, df3.SeconCompanyName)
df3.fillna('', inplace=True)
df3结果2
Stack Overflow用户
发布于 2020-04-22 23:51:41
您可以将每个Child列按其空白拆分,并以顶部n个事件作为您的模式,使用str.extractall提取。
当然,您需要将逻辑调整为用例。
s = df['Child'].str.split(' ',expand=True).stack().value_counts()
pat = '|'.join(s[s.gt(2)].index)
print(pat)
#'CISCO|Systems|CANADA'
df['Parent?'] = df['Child'].str.extractall(f'({pat})').groupby(level=0).agg(','.join)print(df)
Child Parent Parent?
0 MICROSOFT NaN
1 CISCO CISCO
2 CISCO System CISCO
3 CISCO Systems CISCO,Systems
4 CISCO Systems CANADA CISCO,Systems,CANADA
5 CISCO Systems CANADA Corporation CISCO,Systems,CANADA
6 CISCO Systems CANADA Corporation Limited CISCO,Systems,CANADA
7 IBM NaNhttps://stackoverflow.com/questions/61358131
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号