
在SPSS中是否有可能为每个参与者分别创建专题小组/线图?
我试图用随机截距随机斜率模型做纵向分析,。我正在学习Bolger和Laurenceau (2013年)的“强化纵向方法”一书。
作者建议在开始分析之前先看一下数据。他们制作了一个不同的小组图的例子,以看到他们的因变量随时间而变化,分别为每个参与者。
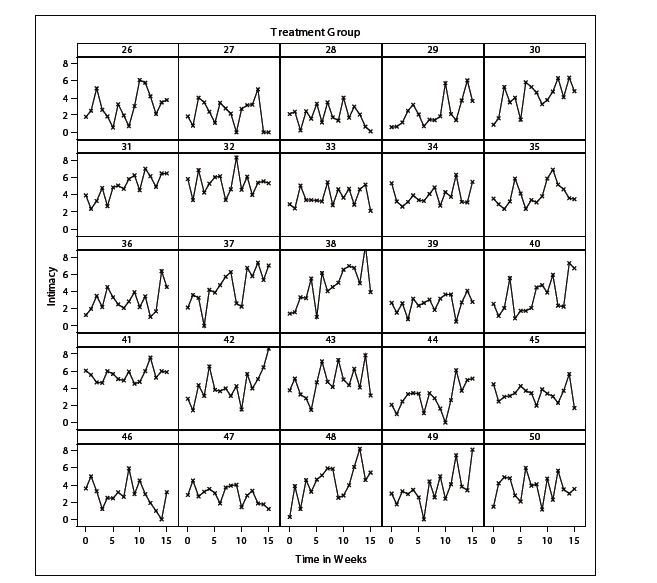
我也想做同样的事情,但是在IBMSPSS26中很难做到这一点。我可以得到我的因变量的线图,但只能从所有参与者一起在一个图。恐怕我看不出这么多,因为上面的线条太多了:
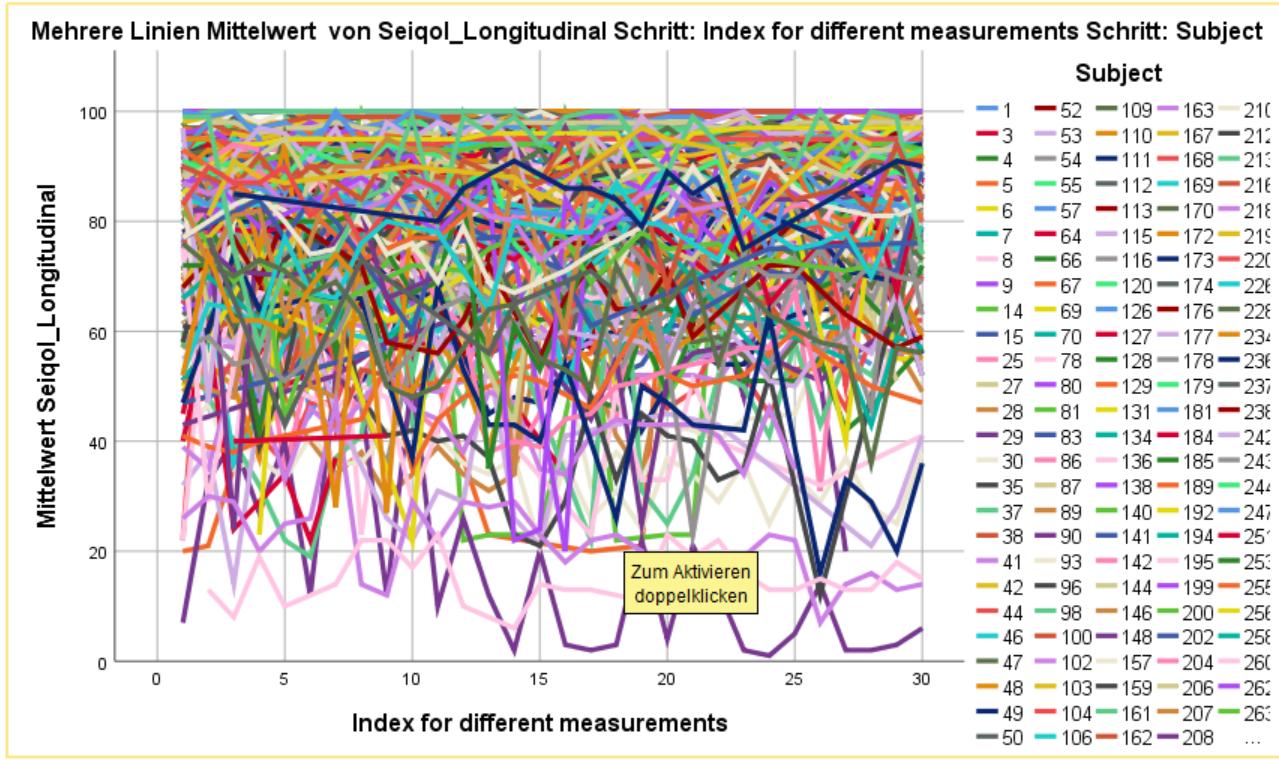
My数据(长格式):
id:我的变量来识别参与者。它重复自己30次(对于每个测量点)。
Index1:是在我将变量从宽格式更改为长格式并指示变量所属的度量点或时点时创建的。从1到30。
Age_Longitudinal:每个参与者有30个年龄值,每个时点有一个值。自变量。
Timepoint:自动创建包含参与者填写问卷的时间和日期的变量。每个参与者有30人。
Date:参与者填写问卷的日期。
SEIQOL_Longitudinal:包含因变量的生活质量的变量。测量了30次。
面板图中应该有y轴处的SEIQOL_Longitudinal和x轴处的Index1来表示时间点。我想为每一位参加者提供个别的“套餐”。没有治疗或控制组(以Bolger和Laurenceau (2013年)为例)。稍后,它可能是有趣的,但也许也可以看看相同的类型的情节分离为2组(老的,老的,年轻的老),这是在名义变量"Agegroup_Longitudinal“中表示的。
有人知道怎么做吗?
回答 1
Stack Overflow用户
发布于 2020-05-15 22:05:10
尝试以下命令(打开语法窗口,复制并粘贴命令,然后打开数据文件,单击Run>All或高亮显示命令,然后单击“绿色箭头”按钮):
GGRAPH
/GRAPHDATASET NAME="graphdataset" VARIABLES=Index1 SEIQOL_Longitudinal id MISSING=LISTWISE REPORTMISSING=NO
/GRAPHSPEC SOURCE=INLINE.
BEGIN GPL
SOURCE: s=userSource(id("graphdataset"))
DATA: Index1=col(source(s), name("Index1"), unit.category())
DATA: SEIQOL_Longitudinal=col(source(s), name("SEIQOL_Longitudinal"))
DATA: id=col(source(s), name("id"), unit.category())
GUIDE: axis(dim(1), label("Index1"))
GUIDE: axis(dim(2), label("SEIQOL_Longitudinal"))
GUIDE: axis(dim(3), label("id"), opposite())
GUIDE: text.title(label("Simple Line of SEIQOL_Longitudinal by Index1 by id"))
COORD: rect(dim(1,2), wrap())
SCALE: linear(dim(2), include(0))
ELEMENT: line(position(Index1*SEIQOL_Longitudinal*id), missing.wings())
END GPL.为此,我在图表编辑器中设置了一个线条图,其中X轴上有Index1,Y轴上有SEIQOL_Longitudinal,还在Groups/Point选项卡上添加了id作为列面板变量。然后,我将命令粘贴到语法窗口中,并添加了COORD: rect(dim(1,2), wrap())语句,我不知道如何在图表编辑器中完成包装。
GUIDE语句中引号中的任何标签都可以根据需要进行更改。
https://stackoverflow.com/questions/61480685
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号