
多进程视频处理
我想在相邻的帧上做视频处理。更具体而言,我想计算相邻帧之间的均方误差:
mean_squared_error(prev_frame,frame)我知道如何以一种简单的线性方式计算这一点:我使用阿穆提斯包来利用队列来解耦、加载和处理帧。通过将它们存储在队列中,我不需要等待它们才能处理它们。...但我想更快.
# import the necessary packages to read the video
import imutils
from imutils.video import FileVideoStream
# package to compute mean squared errror
from skimage.metrics import mean_squared_error
if __name__ == '__main__':
# SPECIFY PATH TO VIDEO FILE
file = "VIDEO_PATH.mp4"
# START IMUTILS VIDEO STREAM
print("[INFO] starting video file thread...")
fvs = FileVideoStream(path_video, transform=transform_image).start()
# INITALIZE LIST to store the results
mean_square_error_list = []
# READ PREVIOUS FRAME
prev_frame = fvs.read()
# LOOP over frames from the video file stream
while fvs.more():
# GRAP THE NEXT FRAME from the threaded video file stream
frame = fvs.read()
# COMPUTE the metric
metric_val = mean_squared_error(prev_frame,frame)
mean_square_error_list.append(1-metric_val) # Append to list
# UPDATE previous frame variable
prev_frame = frame现在我的问题是:我如何对度量的计算进行变异,以提高速度和节省时间?
我的操作系统是Windows 10,我使用python3.8.0
回答 1
Stack Overflow用户
发布于 2020-04-30 23:24:46
让事情变得更快有很多方面,我只想谈一谈多处理部分。
因为你不想一次看完整的视频,所以我们必须一帧一帧地阅读视频。
我将使用opencv (cv2),numpy来读取框架,计算 mse ,并将mse保存到磁盘。
首先,我们可以在不进行任何多处理的情况下开始,这样我们就可以对结果进行基准测试。我使用的视频1920由1080维,60 FPS,持续时间:1:29,大小:100 MB。
import cv2
import sys
import time
import numpy as np
import subprocess as sp
import multiprocessing as mp
filename = '2.mp4'
def process_video():
cap = cv2.VideoCapture(filename)
proc_frames = 0
mse = []
prev_frame = None
ret = True
while ret:
ret, frame = cap.read() # reading frames sequentially
if ret == False:
break
if not (prev_frame is None):
c_mse = np.mean(np.square(prev_frame-frame))
mse.append(c_mse)
prev_frame = frame
proc_frames += 1
np.save('data/' + 'sp' + '.npy', np.array(mse))
cap.release()
return
if __name__ == "__main__":
t1 = time.time()
process_video()
t2 = time.time()
print(t2-t1)在我的系统中,它运行于142秒。
现在,我们可以采用多处理方法。这个想法可以在下面的插图中加以总结。

GIF信贷:Google
我们根据有多少个cpu核来制作一些片段,并并行地处理这些分段帧。
import cv2
import sys
import time
import numpy as np
import subprocess as sp
import multiprocessing as mp
filename = '2.mp4'
def process_video(group_number):
cap = cv2.VideoCapture(filename)
num_processes = mp.cpu_count()
frame_jump_unit = cap.get(cv2.CAP_PROP_FRAME_COUNT) // num_processes
cap.set(cv2.CAP_PROP_POS_FRAMES, frame_jump_unit * group_number)
proc_frames = 0
mse = []
prev_frame = None
while proc_frames < frame_jump_unit:
ret, frame = cap.read()
if ret == False:
break
if not (prev_frame is None):
c_mse = np.mean(np.square(prev_frame-frame))
mse.append(c_mse)
prev_frame = frame
proc_frames += 1
np.save('data/' + str(group_number) + '.npy', np.array(mse))
cap.release()
return
if __name__ == "__main__":
t1 = time.time()
num_processes = mp.cpu_count()
print(f'CPU: {num_processes}')
# only meta-data
cap = cv2.VideoCapture(filename)
width = int(cap.get(cv2.CAP_PROP_FRAME_WIDTH))
height = int(cap.get(cv2.CAP_PROP_FRAME_HEIGHT))
fps = cap.get(cv2.CAP_PROP_FPS)
frame_jump_unit = cap.get(cv2.CAP_PROP_FRAME_COUNT) // num_processes
cap.release()
p = mp.Pool(num_processes)
p.map(process_video, range(num_processes))
# merging
# the missing mse will be
final_mse = []
for i in range(num_processes):
na = np.load(f'data/{i}.npy')
final_mse.extend(na)
try:
cap = cv2.VideoCapture(filename) # you could also take it outside the loop to reduce some overhead
frame_no = (frame_jump_unit) * (i+1) - 1
print(frame_no)
cap.set(1, frame_no)
_, frame1 = cap.read()
#cap.set(1, ((frame_jump_unit) * (i+1)))
_, frame2 = cap.read()
c_mse = np.mean(np.square(frame1-frame2))
final_mse.append(c_mse)
cap.release()
except:
print('failed in 1 case')
# in the last few frames, nothing left
pass
t2 = time.time()
print(t2-t1)
np.save(f'data/final_mse.npy', np.array(final_mse))我只使用numpy save保存部分结果,您可以尝试更好的方法。
使用我的= 12运行49.56秒,当然可以避免一些瓶颈,以使其运行得更快。
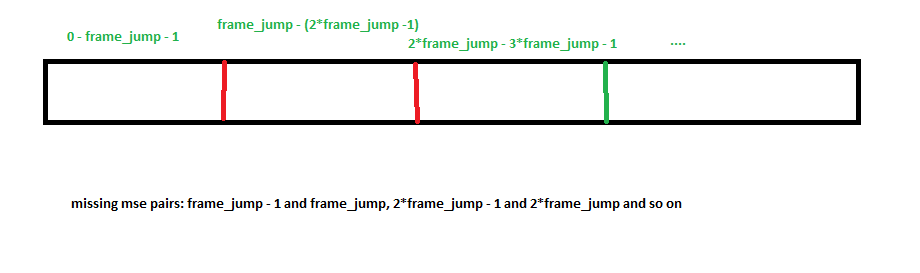
我的实现的唯一问题是,对于视频分割的区域,它缺少mse,很容易添加。由于我们可以用O(1)中的OpenCV在任何位置索引单个帧,所以我们可以直接到这些位置分别计算mse并合并到最终的解决方案。检查更新的代码,它修复合并部分
您可以编写一个简单的检查,以确保,两者提供相同的结果。
import numpy as np
a = np.load('data/sp.npy')
b = np.load('data/final_mse.npy')
print(a.shape)
print(b.shape)
print(a[:10])
print(b[:10])
for i in range(len(a)):
if a[i] != b[i]:
print(i)现在,一些额外的加速可以来自使用CUDA编译的opencv、ffmpeg、添加排队机制和多处理等。
https://stackoverflow.com/questions/61531731
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号