
如何计算绘图时的百分比?
如何计算绘图时的百分比?
提问于 2020-05-02 22:14:11
看看新冠肺炎的数据,我想按百分比绘制每个国家的死亡人数。
目前,我可以按国家分组,把死亡总数汇总如下:
ecdc.groupby("countriesAndTerritories")["deaths"].sum().sort_values(ascending = False).head(10).plot(kind = "bar")这将产生以下情节:
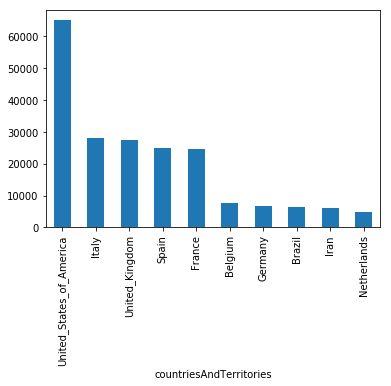
这几乎是我想要的,但我不知道如何从这里/如果我想的方式是可能的。我想使用的另一个字段是popData2018,因此:deaths/popData2018给出了每个国家的死亡百分比。
目前,美国的死亡总人数超过6.5万人,但他们并不是以人口为基础的死亡比例最高的国家(比利时居第一位),我希望我的图表能反映这一点。
我怎样才能做到这一点?
如果你想复制我的作品:
import pandas as pd
ecdc = pd.read_csv("https://opendata.ecdc.europa.eu/covid19/casedistribution/csv")回答 1
Stack Overflow用户
回答已采纳
发布于 2020-05-02 22:45:21
您可以使用以下内容:
(ecdc.groupby('countriesAndTerritories').agg(
total_deaths=('deaths', 'sum'),
population=('popData2018', 'first')
).assign(perc=lambda x: x['total_deaths'] / x['population'])
.nlargest(10, 'perc')
.plot(kind='bar', y='perc')
)或者对于pandas < 0.25.0,我们不能使用named aggregations
(ecdc.groupby('countriesAndTerritories').agg(
{'deaths':'sum',
'popData2018':'first'}
).assign(perc=lambda x: x['deaths'] / x['popData2018'])
.nlargest(10, 'perc')
.plot(kind='bar', y='perc')
),它获取死亡的sum和流行数据,然后创建一个perc列并绘制前10位最高死亡百分比。
或者更多的故障,而不是在一条直线上:
grps = ecdc.groupby('countriesAndTerritories').agg(
total_deaths=('deaths', 'sum'),
population=('popData2018', 'first')
).reset_index()
grps['perc'] = grps['total_deaths'] / grps['population']
grps.nlargest(10, 'perc').plot(kind='bar', x='countriesAndTerritories', y='perc')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61567005
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号