
如何确定临床数据集的数据仓库模式?
我正在为临床数据集( 模拟-III )设计一个模式。我试图找出一种方法来存储事件,以便用户可以使用可能的星型模式轻松地查询数据集。几乎所有的条目,如诊断、程序、记录、图表等,都与一次入院有关。我有一些想法,但我没有经验,所以我发现很难找到最好的方法来做这件事。
- 创建多个事实表,例如,我将有一个用于诊断的事实表,一个用于程序,一个用于实验室记录,但这似乎是没有什么收获的事实表太多了。就像我可以有一个事实表,为每个用户每次入院提供一个条目,但这会给我带来比已经实现的OLTP模式更多的好处吗?
- 创建一个事实表,每张表包含多列/多个维度,如诊断、程序等。但问题是,对于大多数情况下,每次入院都有多个诊断,所以我必须链接到大多数事实表中的桥接表,然后它看起来就像下面的图像。问题是查询所需的联接。
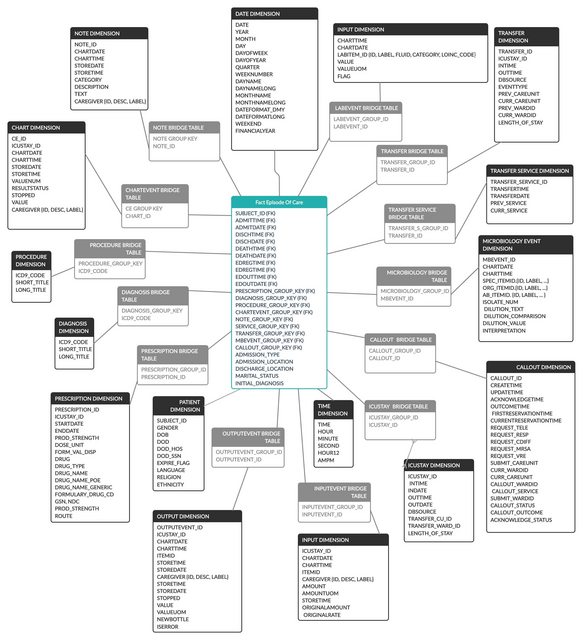
- 我所读到的第三种方法是使用类似于实体属性值事实表的东西,其中我有一个事实表,每一行都是一个事实。例如,一行可能类似于(patientid addmissionid -(属性)心率读取-(值)120 be )-这将创建一个事实表,其中几乎所有的内容都需要加入,但由于EAV的性质,它需要最终用户在查询后将表转到中心,从而使其对最终用户来说更加复杂。它看起来就像i2b2星型模式
- 我想到的最后一种方法是在事实表中对每个事件做一个条目,但是在事实表中有许多列来存储维度,比如(病人、许可、icustay_id、诊断、程序、劳动记录、实验室、微生物事件等等)。在这些条目中,病人和许可将出现在所有行中,但其余的将取决于条目,因此一个条目可能只有耐心、认可和一个过程。我不知道这样做的最终结果会是怎样的,因为我缺乏经验。我也不知道是否所有这些条目与几乎每一列都是无关的。
任何帮助都将是非常感谢的,我正在尝试将其实现到BigQuery中。
回答 2
Stack Overflow用户
发布于 2020-05-14 10:05:59
一些测试得出结论,减少联接的数量可以提高BigQuery的性能。换句话说,如果您在一个表中对大部分数据进行去或删除,您可能会得到更好的结果,因为您不需要执行许多联接。
在决定数据建模时,您应该考虑以下几点:
在您的模型中编写查询容易吗?
如果您需要许多联接,您的模型可能很难构建查询。如果使用嵌套字段来减少联接的数量,则可以简化将要编写的查询。但是,如果您创建非常复杂的嵌套结构,您将开始再次查询模型时出现问题。
在您的模型中很容易连接数据吗?
如果您有许多表要连接,您的数据将难以连接。数据越不规范,加入起来就越容易。
易于更新数据
如果您需要更新您的数据,您应该考虑去规范化可以帮助您。如果减少了表的数量,则需要更新更少的表。重要的是,如果您创建非常复杂的嵌套字段,它也将很难被更新。
使数据可以理解
这是最重要的一点。在给定的模型中,您的数据可以理解吗?前面的所有要点都是技术性的,与您的数据不完全相关。您应该考虑到这些点来设计您的模型,但是您的数据必须对您有意义。
最后,我想总结一些建议:
- 只要数据保持可理解性,您就可以获得更好的性能去错误处理数据。
- 使用嵌套字段对模型进行去奥化,但不要创建非常复杂的结构(嵌套级别超过2级)。
- 请记住,您的模型需要更多的磁盘空间,当您对它进行反错处理时,您在
BigQuery中存储的账单可能会更高。
我希望它能帮上忙
Stack Overflow用户
发布于 2020-05-21 05:15:58
初读
试着阅读数据仓库工具包,第14章有一个关于医疗数据建模的章节。
建模与存储
但是你应该试着找出什么是重要和高价值的数据,什么是不太重要和低价值的数据。只有将高值数据建模并加载到数据库中。如果您尝试构建完美的数据模型,就永远不会向您的客户/客户提供任何有用的报告。
- 每天或每小时使用什么?这些信息需要在您的数据模型中,并加载到数据库中进行聚合和切片。
- 什么只会偶尔使用?一旦切片和切块完成,就会有更多关于一个小群体的细节的问题。这是当您进入大容量存储并从data检索此数据时。
数据湖
仪器测量是低值信息的很好例子。大多数单独的度量并不有用,但是您的ETL可以检查它们并做出某种类型的总体决定。例如血压正常、心率高等。处方药是另一个低价值信息的例子。在数据库中,如果存在多个处方或类似的东西,您可以设置一个标志。自由形式的笔记是另一种。一旦根据许多其他因素确定了一些队列,您就可以让数据科学家通过一些机器学习来处理这个注释,但是对所有的注释都这样做并不是很有用。
组/垃圾尺寸
这些测量结果中的一些可以集中在一个组/垃圾维度中,作为一种解决事实的方法,并防止事实以低值行爆炸。您甚至可以推迟对垃圾维度的建模,直到您的客户/客户端开始告诉您特定类型数据提取的长时间执行。然后,您可以设计一个垃圾维度,以便在从数据湖中提取有洞察力的数据之前,为这些更高值的度量确定提供额外的聚合或切片。
文件结构
在您的数据湖中,我将有许多低值数据的文件模式。这些可以是JSON,parquet,csv,或者您喜欢的任何东西。您将包括将其连接回事实所需的数据以及特定于文件类型的数据。PatientId AdmissionId MeasureType MeasureValue日期时间
关键是这些数据中的大部分永远不会被查看,但偶尔也会有一些记录具有很高的价值。你只是不知道它们会是哪一个,所以你尽可能便宜地储存它们,直到它们被需要为止。
数据池还允许您在新信息可用时更改文件模式,执行此更改与更改数据库星型相比非常简单。
使用您最喜欢的脚本语言创建这些文件。Python,C#,Azure函数应用程序,AWS,什么的。这将取决于你自己的技能和资源。
https://stackoverflow.com/questions/61719671
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号