
根据箭头标记识别汽车的部件
Please excuse me for not posting any code, as I don't think I have reached far enough to be relevant for my question.
我正在研究一种解决方案,需要识别客户绘图所指向的车辆部件,并提取文本及其引用的部分,如下面的示例所示。
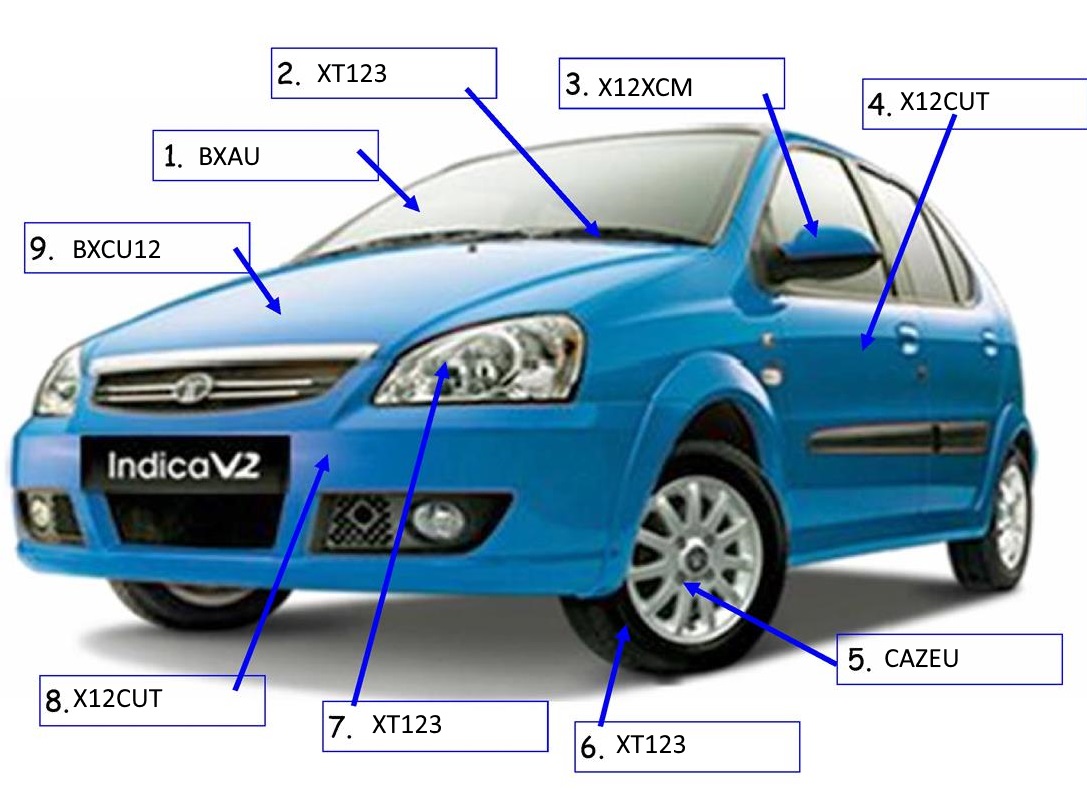
我对ML或AI技术非常陌生,因此我正在考虑使用Azure customvision.ai,它允许我使用一堆图像和对象标识来训练模型,并且有一个很好的REST。这有点工作,因为我能够传递图像,它能够识别汽车的部分可见在该图像。
但是,我无法理解如何识别9. BXCU12实际上指向Bonnet。
有人能帮我指出任何例子或适当的解决方法为我解决这个问题。
回答 1
Stack Overflow用户
发布于 2020-05-29 19:10:01
如果我的理解是正确的,你已经可以从你的识别网络和文本中识别出部分,它们之间的链接是由图像中的箭头给出的,你不知道如何定位。所以,这里剩下的问题是探测箭头和它们的端点。
我现在可以想到两种解决方案:
1)使用模板匹配来识别箭头。但是,在您的情况下,问题(从您的示例图像)似乎是,您的箭头具有相同的比例,但有不同的长度。所以,我建议只使用箭头的头部+一个很短的尾巴作为模板。然后,您可以旋转这个小模板N次,获得N个模板,并使用类似什么opencv以模板匹配的方式提供。
2)训练一个小卷积神经网络来识别箭头。您只想识别箭头,所以很容易创建一个小的不同尺度旋转箭头的数据集,并在它们上训练网络。请注意,您可能应该能够将这个网络添加到您的识别网络中,作为一个额外的、非常浅的头(您需要联合改进),因此开销将是最小的。
希望这能有所帮助。
https://stackoverflow.com/questions/61893268
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号