
如何过滤可积数据列中的NA值?
如何过滤可积数据列中的NA值?
提问于 2020-05-23 12:53:04
我有一个数据表,
DT_EX= dt.Frame({
'country':['a','a','a','a'],
'id':[3,3,3,3],
'shop':['dmart','dmart','dmart','dmart'],
'beef':[23,None,None,None],
'eggs':[None,33,None,None],
'fork':[None,None,10,None],
'veg':[None,None,None,40]})它的输出是,
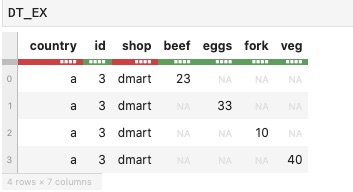
我想把它转换成datatable,它在列中不应该有NA,如这个输出所示,
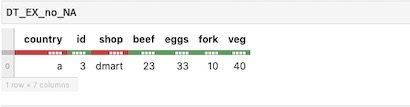
请您解释一下如何在py-datatable上执行此操作(移除NA)吗?dt.isna()在这种情况下会有帮助吗?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-05-23 13:26:38
一种方法是选择前三列(它们没有空),然后用其余列之和扩展它:链接
from datatable import f, first, sum
DT_EX[:,first(f[:3]).extend(sum(f[3:]))]
country id shop beef eggs fork veg
▪▪▪▪ ▪▪▪▪ ▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪ ▪▪▪▪▪▪▪▪
0 a 3 dmart 23 33 10 40更新:另一个相关问题的简单解决方案:
DT_EX[:, sum(f[3:]), f[:3])]Stack Overflow用户
发布于 2020-05-23 15:37:42
我还有一个子群的项目,这是一个新的DT。
DT_EX= dt.Frame({
'country':['a','a','a','a','b','b','c','c'],
'id':[3,3,3,3,4,4,4,4],
'shop':['dmart','dmart','dmart','dmart','amzn','amzn','amzn','amzn'],
'beef':[23,None,None,None,93,None,None,None],
'eggs':[None,33,None,None,None,103,None,None],
'fork':[None,None,10,None,None,None,210,None],
'veg':[None,None,None,40,None,None,None,340]})我试着在上面加上推荐的逻辑,如下面的截图中所示,
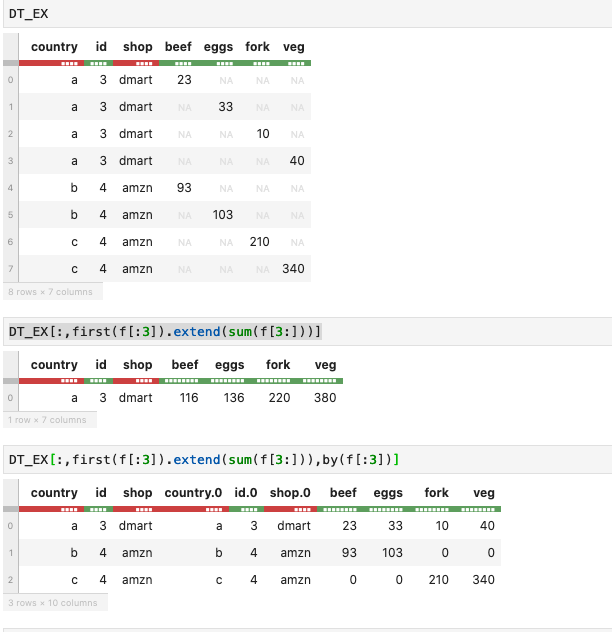
在第二个代码块中,它总结了每一列(牛肉、鸡蛋、叉子、蔬菜)。
在第三个代码块中,我对前三列进行了分组,这里给出了一个正确的输出,但是它添加了重复的列,另一个观察是它用0填充NA值,它可以在C观察中找到。
你对此还有什么其他的想法/建议吗?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/61972339
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号