
Python功能工程师移动数据
嗨,我正在尝试设计一个从运动水平到病人级别的病人数据集。
原始df如下所示:
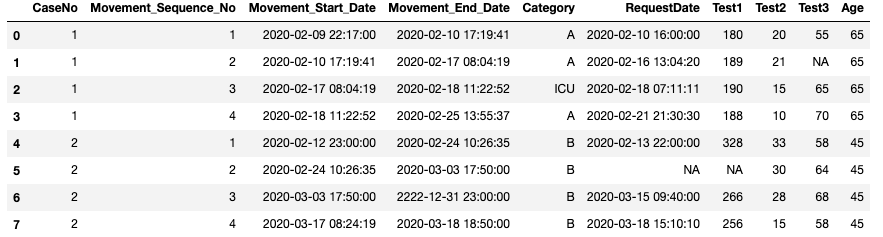
条件:
1)创建Last Test<n> Change cols -用于遇到Category值“ICU”的CaseNo,在“ICU”值之前进行Test<n>更改( Test1值为189-180,CaseNo 1),否则采用最新的Test<n>更改( Test1、CaseNo 2为256-266)。
2)创建Test<n>_Pattern cols --对于遇到Category值‘Category’的CaseNo,将所有的Test<n>值从开始到“ICU”值之前进行传递。否则,将所有Test<n>值从开始到结束。
3)创建Last Test<n> Count cols -对于遇到Category值‘Category’的CaseNo,在“ICU”相遇之前取最后一个Test<n>值。否则,取最后一个Test<n>值。
预期结果

我怎么用Python来做这件事?
用于df的代码
df = pd.DataFrame({'CaseNo':[1,1,1,1,2,2,2,2],
'Movement_Sequence_No':[1,2,3,4,1,2,3,4],
'Movement_Start_Date':['2020-02-09 22:17:00','2020-02-10 17:19:41','2020-02-17 08:04:19',
'2020-02-18 11:22:52','2020-02-12 23:00:00','2020-02-24 10:26:35',
'2020-03-03 17:50:00','2020-03-17 08:24:19'],
'Movement_End_Date':['2020-02-10 17:19:41','2020-02-17 08:04:19','2020-02-18 11:22:52',
'2020-02-25 13:55:37','2020-02-24 10:26:35','2020-03-03 17:50:00',
'2222-12-31 23:00:00','2020-03-18 18:50:00'],
'Category':['A','A','ICU','A','B','B','B','B'],
'RequestDate':['2020-02-10 16:00:00','2020-02-16 13:04:20','2020-02-18 07:11:11','2020-02-21 21:30:30',
'2020-02-13 22:00:00','NA','2020-03-15 09:40:00','2020-03-18 15:10:10'],
'Test1':['180','189','190','188','328','NA','266','256'],
'Test2':['20','21','15','10','33','30','28','15'],
'Test3':['55','NA','65','70','58','64','68','58'],
'Age':['65','65','65','65','45','45','45','45']})预期结果:
df2 = pd.DataFrame({'CaseNo':[1, 2],
'Last Test1 Change':[9, -10],
'Test1 Pattern':['180, 189', '328, 266, 256'],
'Last Test1 Count':[189, 256],
'Last Test2 Change':[1, -13],
'Test2 Pattern':['20, 21', '33, 30, 28, 15'],
'Last Test2 Count':[21, 15],
'Last Test3 Change':[10, -10],
'Test3 Pattern':['55', '58, 64, 68, 58'],
'Last Test3 Count':[55, 58],
'Age':[65, 45]})回答 2
Stack Overflow用户
发布于 2020-05-28 13:36:39
试着这样做:
df = pd.DataFrame({'CaseNo':[1,1,1,1,2,2,2,2],
'Movement_Sequence_No':[1,2,3,4,1,2,3,4],
'Movement_Start_Date':['2020-02-09 22:17:00','2020-02-10 17:19:41','2020-02-17 08:04:19',
'2020-02-18 11:22:52','2020-02-12 23:00:00','2020-02-24 10:26:35',
'2020-03-03 17:50:00','2020-03-17 08:24:19'],
'Movement_End_Date':['2020-02-10 17:19:41','2020-02-17 08:04:19','2020-02-18 11:22:52',
'2020-02-25 13:55:37','2020-02-24 10:26:35','2020-03-03 17:50:00',
'2222-12-31 23:00:00','2020-03-18 18:50:00'],
'Category':['A','A','ICU','A','B','B','B','B'],
'RequestDate':['2020-02-10 16:00:00','2020-02-16 13:04:20','2020-02-18 07:11:11','2020-02-21 21:30:30',
'2020-02-13 22:00:00','NA','2020-03-15 09:40:00','2020-03-18 15:10:10'],
'Test1':['180','189','190','188','328','NA','266','256'],
'Test2':['20','21','15','10','33','30','28','15'],
'Test3':['55','NA','65','70','58','64','68','58'],
'Age':['65','65','65','65','45','45','45','45']})
# simple data management
df = df.replace('NA', np.nan)
df[['Test1','Test2','Test3','Age']] = df[['Test1','Test2','Test3','Age']].astype(float)
# create empty df to store results
results = pd.DataFrame()
# split original df in groups based on CaseNo
for jj,(j,gr) in enumerate(df.groupby('CaseNo')):
group = gr.copy()
# idenfify the presence of ICU
group['Category'] = (group['Category'].values == 'ICU').cumsum()
# replace NaN value with the next useful value
# this is useful to fill NaN in Test1, Test2, Test3
group_fill = group.fillna(method='bfill')
# select part of df before the first ICU matched
group_fill = group_fill[group_fill.Category == 0]
group = group[group.Category == 0]
# at this point we have two copy of our group df (group and group_fill)
# group contains the raw (inclused NaN) values for a selected CaseNo
# group_fill contains the filled values for a selected CaseNo
# create empty df to store partial results
partial = pd.DataFrame()
# select unique CaseNo
partial['CaseNo'] = group['CaseNo'].unique()
# for loop to make operation on Test1, Test2 and Test3
for i in range(1,4):
# these are simply the operation you required
# NB: 'Last TestN Change' is computed on the group df without NaN
# this is important to avoid errors when the last obsevarion is NaN
# 'TestN Pattern' and 'Last TestN Count' can be computed on the filled group df
partial[f'Last Test{i} Change'] = group_fill[f'Test{i}'].tail(2).diff().tail(1).values
partial[f'Test{i} Pattern'] = [group[f'Test{i}'].dropna().to_list()]
partial[f'Last Test{i} Count'] = group[f'Test{i}'].dropna().tail(1).values
# select unique age
partial['Age'] = group['Age'].unique()
# create correct index for the final results
partial.index = range(jj,jj+1)
# append partial results to final results df
results = results.append(partial)
# print final results df
results

Stack Overflow用户
发布于 2020-05-26 04:45:50
我只想告诉你怎么用一般的方法来处理你的问题。
对于第一个条件,您可以通过cumsum创建一个助手索引,以便在ICU之后过滤掉数据:
df["helper"] = df.groupby("CaseNo")["Category"].transform(lambda d: d.eq("ICU").cumsum())我不太清楚n代表什么,但是如果您只想获取一定数量的数据,请使用groupby和tail
s = df.loc[df["helper"].eq(0)].groupby("CaseNo").tail(4).filter(regex="CaseNo|Test.*|Age")
print (s)
CaseNo Test1 Test2 Test3 Age
0 1 180.0 20.0 55.0 65
1 1 189.0 21.0 NaN 65
4 2 328.0 33.0 58.0 45
5 2 NaN 30.0 64.0 45
6 2 266.0 28.0 68.0 45
7 2 256.0 15.0 58.0 45最后,pivot您的数据:
res = (pd.pivot_table(s, index=["CaseNo", "Age"],
aggfunc=["last", list]).reset_index())
print (res)
CaseNo Age last list
Test1 Test2 Test3 Test1 Test2 Test3
0 1 65 189.0 21.0 55.0 [180.0, 189.0] [20.0, 21.0] [55.0, nan]
1 2 45 256.0 15.0 58.0 [328.0, nan, 266.0, 256.0] [33.0, 30.0, 28.0, 15.0] [58.0, 64.0, 68.0, 58.0]从这里开始,你可以朝着你的最终目标努力。
https://stackoverflow.com/questions/62014338
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号