
从核密度估计中获取核特性(sklearn)
从核密度估计中获取核特性(sklearn)
提问于 2020-05-27 20:05:14
在滑雪范例中,合成的数据来自两个高斯分布的加权抽样,[0,1]和[5, 1]的均值和std分别占30%和70%。假设使用gaussian内核和bandwidth=1,我们得到了以下结果( KDE估计器的输出与列车数据相匹配):
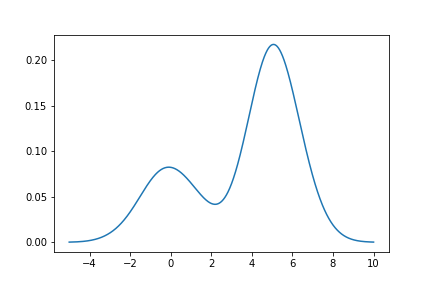
是否有可能(从数学上和实际上)恢复估计核的特性?例如,在这种情况下,我们从拟合模型中读取[0,1]和[5, 1]值?(假设适当地完成了拟合过程)
回答 1
Stack Overflow用户
发布于 2022-03-29 04:51:41
不这是不可能的。
sklearn类只允许(1)采样新的数据点,(2)计算模型下的日志似然。在您的示例中,您可以通过眼睛读取高斯混合模型的均值和标准差,但这与核密度估计下的算法无关。
sklearn算法的标准工作流程如下:
- 用所选的超参数实例化KDE实例(特别是提供内核和带宽)。
fit()方法将训练数据集分配给KDE实例。这里的文档:https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KernelDensity.html#sklearn.neighbors.KernelDensity.fitsample()方法通过以下方式生成新的数据点:(i)首先随机选择训练数据集中的数据点x;(ii)从以x为中心的正态分布中抽取一个随机实例,其中以标准偏差h(h是您的KDE带宽)为中心。- 使用
score()和score_sample()计算模型下生成的样本的日志可能性。
因此,不存在“估计核的特性”这样的东西。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62051931
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号