
R-查找只有x列不同的相同行或行。
我试图在一个大的CSV文件上使用R,在这个例子中,可以说它代表了一个人和交通工具的列表。如果一个人拥有这种运输方式,这是由相应单元格中的X表示的。这方面的示例数据如下:
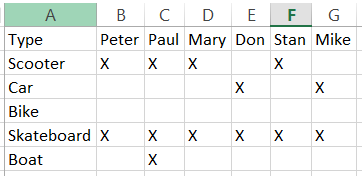
Type,Peter,Paul,Mary,Don,Stan,Mike
Scooter,X,X,X,,X,
Car,,,,X,,X
Bike,,,,,,
Skateboard,X,X,X,X,X,X
Boat,,X,,,,下面的图像使您更容易看到它所代表的内容:
我想要了解的是,哪些人的交通方式是相同的,或者,理想的情况下,哪里的交通方式相差不超过一种。
这种格式有点奇怪,但假设csv文件名为example.csv,我可以将它读取到数据帧中,并按以下所示进行转换(很明显,我是一个完整的R)。
ex <- read.csv('example.csv')
ext <- as.data.frame(t(ex))这个职位解释了如何找到副本,而且它似乎很有效。
duplicated(ext) | duplicated(ext[nrow(ext):1, ])[nrow(ext):1]
which(duplicated(ext) | duplicated(ext[nrow(ext):1, ])[nrow(ext):1])这将返回以下索引:
1 2 4 5 6 7
{kind=link}
这确实与我认为是重复行的内容相对应。也就是说,彼得和玛丽和斯坦有着相同的交通方式(索引2,4和6);唐和迈克同样有相同的交通方式,索引5和7。
同样,这似乎还可以,但是如果交通方式和人数很重要,那么就很难找到/知道哪些行是重复的,哪些索引实际上是匹配的。在这种情况下,索引2、4和6是相同的,而5和7是相同的。
是否有一种简单的方法可以获得这些信息,这样就不需要手动查找匹配的信息了?
此外,鉴于上述所有情况,是否有可能以任何方式修改代码,以便在X位置只有不同的情况下考虑行进行匹配(例如,只要上面示例中的人员没有超过一种不同的运输方式,则仍然被认为是匹配的)?
很高兴进一步详细阐述,非常感谢您的任何帮助。
回答 1
Stack Overflow用户
发布于 2020-05-29 14:49:45
library(dplyr)
library(tidyr)
ex <- read.csv(text = "Type,Peter,Paul,Mary,Don,Stan,Mike
Scooter,X,X,X,,X,
Car,,,,X,,X
Bike,,,,,,
Skateboard,X,X,X,X,X,X
Boat,,X,,,,", )
ext <- tidyr::pivot_longer(ex, -Type, names_to = "person")
# head(ext)
ext <- ext %>%
group_by(person) %>%
filter(value == "X") %>%
summarise(Modalities = n(), Which = paste(Type, collapse=", ")) %>%
arrange(desc(Modalities), Which) %>%
mutate(IdenticalGrp = rle(Which)$lengths %>% {rep(seq(length(.)), .)})
ext
#> # A tibble: 6 x 4
#> person Modalities Which IdenticalGrp
#> <chr> <int> <chr> <int>
#> 1 Paul 3 Scooter, Skateboard, Boat 1
#> 2 Don 2 Car, Skateboard 2
#> 3 Mike 2 Car, Skateboard 2
#> 4 Mary 2 Scooter, Skateboard 3
#> 5 Peter 2 Scooter, Skateboard 3
#> 6 Stan 2 Scooter, Skateboard 3要在任何特定的IndenticalGrp中获得成员列表,您只需像这样的pull。
ext %>% filter(IdenticalGrp == 3) %>% pull(person)
#> [1] "Mary" "Peter" "Stan"https://stackoverflow.com/questions/62085543
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号