
selenium Zillow学校中的XPATH
试图创建一个程序,在网络上为某个社区的学校抓取Zillow,但我在为学校信息(评级、学校名称和年级)抓取xpath时遇到了一些困难。
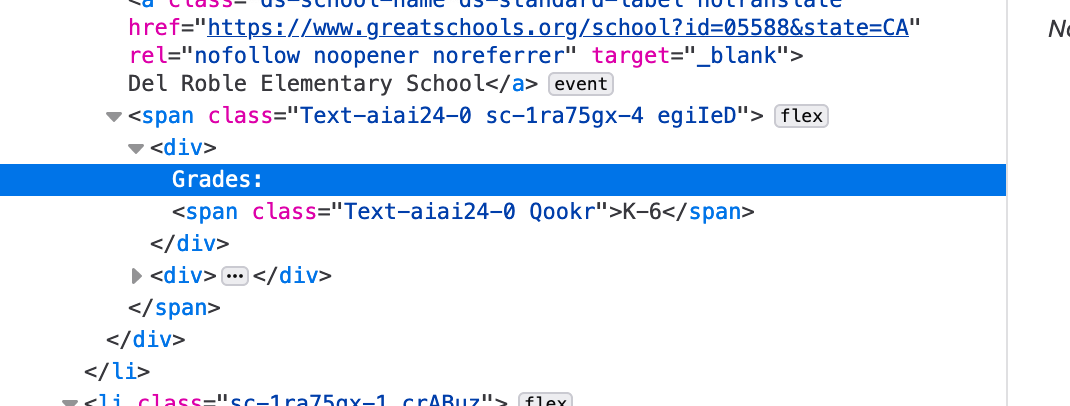
我没有运气获得这个分数: 4/10和学校名称,见图:
我已经尝试了'4':driver.find_element_by_xpath('.//div[@class="sc-1ra75gx-0 eYkapv"]/span[@class="Text-aiai24-0 egyxfz"]').text),但是它失败了(没有输出)。我试着得到学校的名字,在这个例子中,Del Roble小学,它也没有返回正确的输出。(driver.find_element_by_xpath('(.//div[@class="sc-1ra75gx-3 fnKRzv"]/span[@class="ds-school-name ds-standard-label notranslate"])[1]').text)和它没有输出任何东西。

当我试图为我所用的某所学校的成绩而努力的时候:
(driver.find_element_by_xpath("//span[@class='Text-aiai24-0 Qookr']").text),但它返回“估计月收入”,我猜是因为它使用相同的span类,所以我如何才能获得分数而不是另一个。
我试图按以下方式获得输出:
School: Del Roble Elementary School
Rating: 4/10
Grade: K-6# IT WORKS
import pandas as pd
from selenium import webdriver
import time
# Open the browser and URL
h_count = 3
driver = webdriver.Firefox()
#url ="https://www.zillow.com/homes/for_sale/33839_rid/2-_beds/84000-1979000_price/X1-SSg18dep4cy1ee1000000000_1y8ew_sse/?searchQueryState=%7B%22pagination%22%3A%7B%7D%2C%22mapBounds%22%3A%7B%22west%22%3A-121.96676450598144%2C%22east%22%3A-121.75905423986816%2C%22south%22%3A37.25989406246074%2C%22north%22%3A37.36706818940328%7D%2C%22regionSelection%22%3A%5B%7B%22regionId%22%3A33839%2C%22regionType%22%3A6%7D%5D%2C%22isMapVisible%22%3Atrue%2C%22mapZoom%22%3A12%2C%22filterState%22%3A%7B%22price%22%3A%7B%22min%22%3A84000%2C%22max%22%3A1979000%7D%2C%22beds%22%3A%7B%22min%22%3A2%7D%2C%22sort%22%3A%7B%22value%22%3A%22globalrelevanceex%22%7D%7D%2C%22isListVisible%22%3Atrue%7D"
url = "https://www.zillow.com/san-jose-ca/schools/"
driver.get(url)
driver.maximize_window()
time.sleep(2)
name = driver.find_element_by_xpath('//header[@class="school-name"]/@href[1]')
#rate = driver.find_element_by_xpath('//div[@class="zsg-media-img_ext school-card-rating"]/div')
info = driver.find_element_by_xpath('//span[@class="school-fact school-grade"][1]')
print("name: " + str(name))
print("rating: " + str(rate))
print("info: " + str(info))回答 1
Stack Overflow用户
发布于 2020-06-02 02:28:52
你也许应该从这里开始,从感兴趣的学校开始:
https://www.zillow.com/san-jose-ca/schools/#/san-jose-ca/schoolsDel Roble Elementary School出现在第8页。
要从结果列表中刮取学校名称、学校评级和年级,可以使用以下XPath:
//header[@class="school-name"]/a
//li//div[contains(@class,"gs-rating")]
//li[@class="school-card-info-item"][1]最后一个表达式的结果将需要进行一些清理(删除"XXXX·档次.“的第一部分)。有点像result.partition("• ")[2]
或者,假设您根据//header[@class="school-name"]//@href的结果列表构建了一个学校列表,您可以使用以下方法处理每个页面:
//h1
//div[@class="zsg-media-img_ext school-card-rating"]/div
//span[@class="school-fact school-grade"]德尔·罗布尔的输出:Del Roble, 4, Grades-K6
要完成,您还可以直接下载JSON格式的数据(每个JSON有200所学校)。要构建正确的请求URL并假设搜索了"San Jose“(https://www.zillow.com/san-jose-ca/schools/),请执行以下操作:
查找以下元素:
//div[@class="zsg-layout-width zsg-layout-top"]/div[1]获取属性@data-id (城市id)和@data-mbr(坐标位置)。对于data-mbr,您必须删除( )。
在圣何塞,你会发现33839和-122.045672,37.147971,-121.704359,37.469538
您可以构建url来获取JSON,如下所示:
https://www.zillow.com/ajax/schools.json?bb=value.of.data.mbr&sort=gs_rating&dir=desc&r=value.of.data.id如果结果数超过200,则添加&page=XX (这可以在以下元素//section[@class="school-region-about zsg-content-section"]//p中找到)。
用于圣何塞的JSON urls:
然后使用import json、json.load对数据进行过滤。
产出:

https://stackoverflow.com/questions/62142417
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号