
Matplotlib -时间序列分析Python
我试图使用这些数据(https://gist.github.com/datomnurdin/33961755b306bc67e4121052ae87cfbc)创建两种类型的时间序列。首先,每天要数多少次。第二,每天的总情绪。
每天第二次总情绪的代码。
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('data_filtered.csv', parse_dates=['date'], index_col='date')
def plot_df(df, x, y, title="", xlabel='Date', ylabel='Value', dpi=100):
plt.figure(figsize=(16,5), dpi=dpi)
plt.plot(x, y, color='tab:red')
plt.gca().set(title=title, xlabel=xlabel, ylabel=ylabel)
plt.show()
plot_df(df, x=df.index, y=df.sentiment, title='Sentiment Over Time')第二次系列图对我来说没有任何意义。也有可能保存这个数字供将来参考。
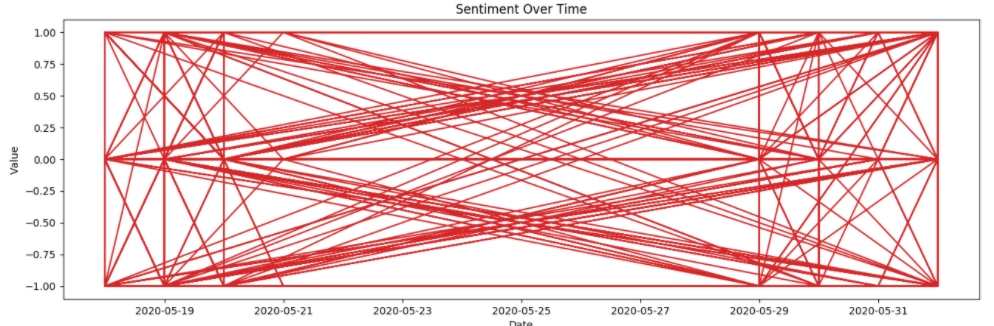
回答 2
Stack Overflow用户
发布于 2020-06-04 16:36:35
试着检查源数据。
date
如果我试图用以下代码绘制date发行版:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('data_filtered.csv', parse_dates = ['date'])
df['date'].hist()
plt.show()我得到:
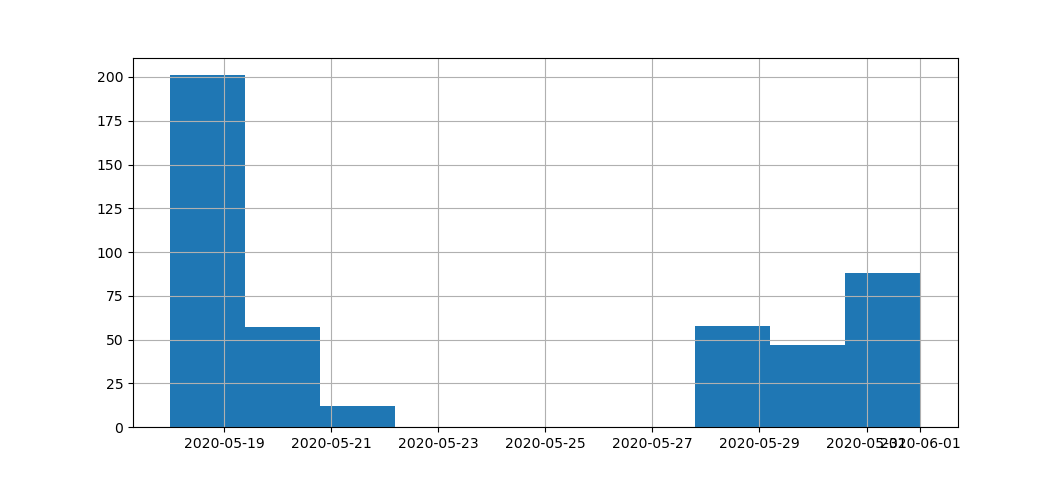
如您所见,大多数date值集中在2020-05-19或2020-05-30上,两者之间没有关系。所以,只在图的左边和右边,而不是在中间看到点是有意义的。
情操
如果我试图用以下代码绘制sentiment发行版:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('data_filtered.csv', parse_dates = ['date'])
df['sentiment'].hist()
plt.show()我得到:
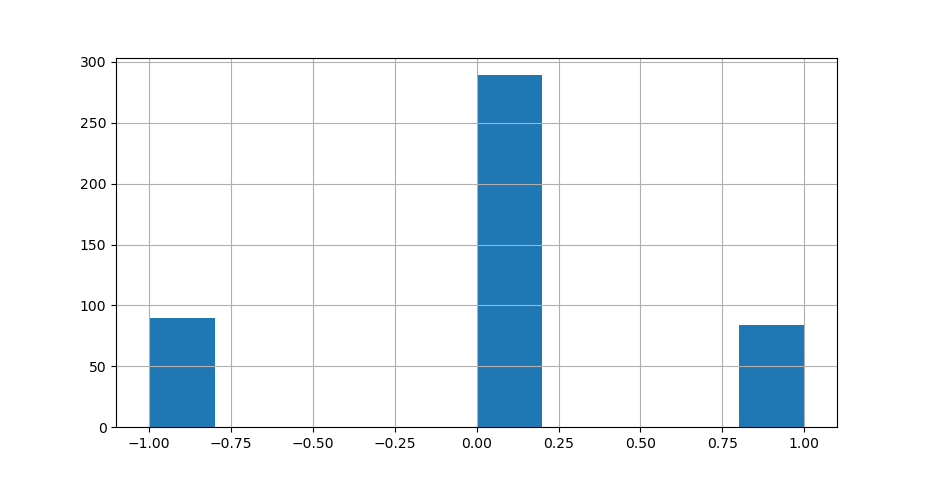
如您所见,sentiment值集中在三个组中:-1、0和1;没有其他值。所以,只在图的底部、中间和顶部看到点是有意义的,而不是在其他地方。
散射图
最后,我尝试将date和sentiment合并成一个散点图:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('data_filtered.csv', parse_dates = ['date'])
fig, ax = plt.subplots(1, 1, figsize = (16, 5))
ax.plot(df['date'], df['sentiment'], 'o', markersize = 15)
ax.set_title('Sentiment Over Time')
ax.set_xlabel('Date')
ax.set_ylabel('Value')
plt.show()我得到了:
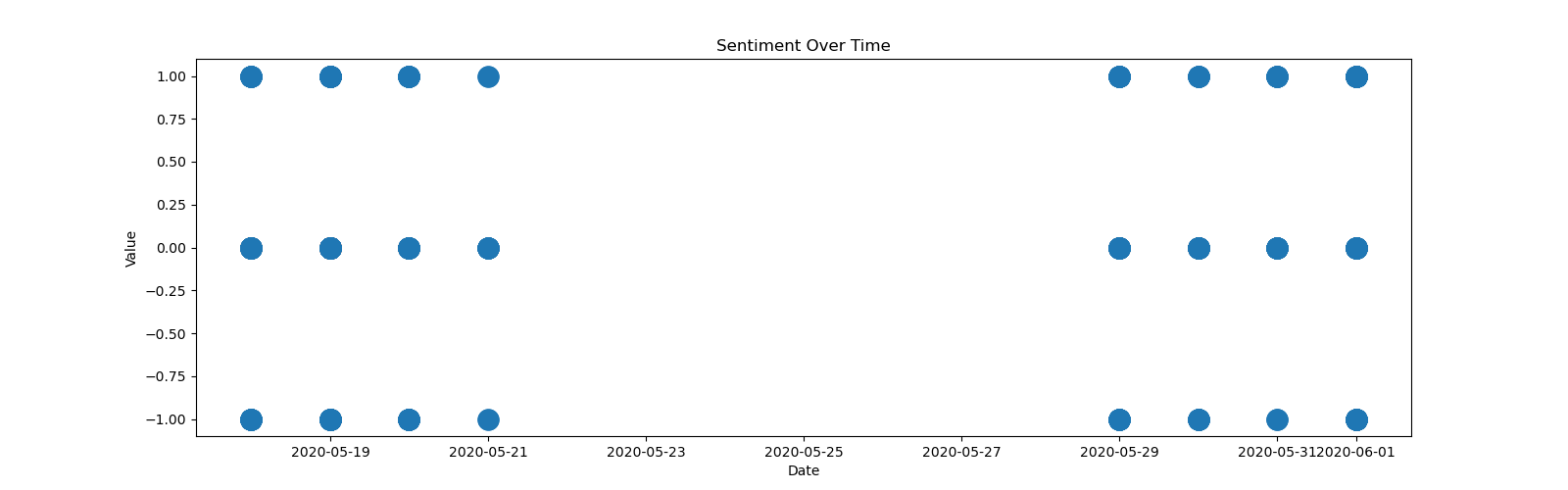
这正是你的图形,但这些点不是由一条线连接起来的。您可以看到这些值是如何集中在特定区域而不是分散的。
累积
如果要通过sentiment聚合date值,请检查以下代码:
import matplotlib.pyplot as plt
import pandas as pd
df = pd.read_csv('data_filtered.csv', parse_dates = ['date'])
df_cumulate = df.groupby(['date']).sum()
def plot_df(df, x, y, title="", xlabel='Date', ylabel='Value', dpi=100):
plt.figure(figsize=(16,5), dpi=dpi)
plt.plot(x, y, color='tab:red')
plt.gca().set(title=title, xlabel=xlabel, ylabel=ylabel)
plt.savefig('graph.png')
plt.show()
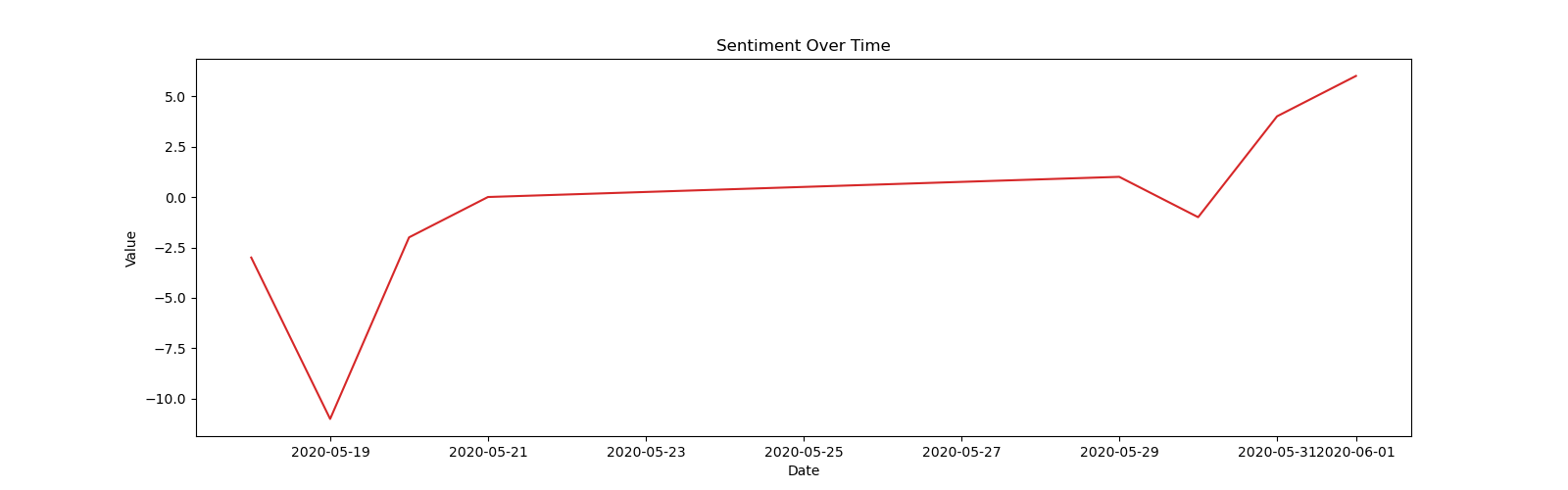
plot_df(df_cumulate, x=df_cumulate.index, y=df_cumulate.sentiment, title='Sentiment Over Time')我通过行df = pd.read_csv('data.csv', parse_dates = ['date'])聚合数据;这里是sentiment随时间累积的图:
Stack Overflow用户
发布于 2020-06-04 16:31:46
链接到的数据有八个不同的日期。
如果您只是简单地复制/粘贴,则日期不会被解释为时间点,而是被解释为字符串。
您可以通过转换为datetime对象来更改这一点:
#convert to datetime
df['date'] = pd.to_datetime(df['date'])图中的连接来自这样一个事实,即数据点的索引确定何时绘制,但其x-坐标(此处: date)的值决定绘制的位置。由于plt.plot是一种连接数据点的方法,一个接一个地绘制的数据点将与一条线连接,而不管它们将在何处结束。通过对数据进行排序,可以对齐时间点和位置:
#then sort by date
df.sort_values(by='date', inplace=True)这并不是一个容易解释的情节,但至少现在您知道哪些行来自何处:

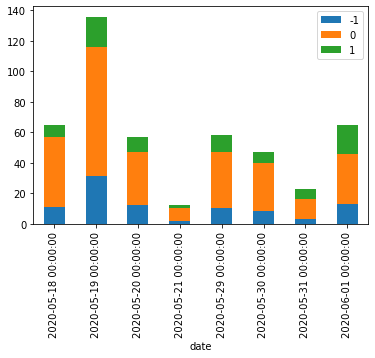
绘制数据的一个更好的方法是一张堆叠的条形图:
a=df.groupby(['date', 'sentiment']).agg(len).unstack()
a.columns = ['-1', '0', '1']
a[['-1', '0', '1']].plot(kind='bar', stacked=True)
https://stackoverflow.com/questions/62197842
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号