
数据库笔记本在内存作业中崩溃
数据库笔记本在内存作业中崩溃
提问于 2020-06-09 04:45:47
我很少运行操作来在上聚合大量的数据(大约600 of )。最近我注意到笔记本崩溃了,databricks返回了下面的错误。在较小的6个节点集群中,相同的代码可以工作。在将它升级到12个节点之后,我开始得到它,并且我怀疑它是否是一个配置问题。
请提供任何帮助,我使用分区number=200的默认星火配置,并且我的节点上有88个执行器。
Thanks
Internal error, sorry. Attach your notebook to a different cluster or restart the current cluster.
java.lang.RuntimeException: abort: DriverClient destroyed
at com.databricks.backend.daemon.driver.DriverClient.$anonfun$poll$3(DriverClient.scala:381)
at scala.concurrent.Future.$anonfun$flatMap$1(Future.scala:307)
at scala.concurrent.impl.Promise.$anonfun$transformWith$1(Promise.scala:41)
at scala.concurrent.impl.CallbackRunnable.run(Promise.scala:64)
at com.databricks.threading.NamedExecutor$$anon$2.$anonfun$run$1(NamedExecutor.scala:335)
at scala.runtime.java8.JFunction0$mcV$sp.apply(JFunction0$mcV$sp.java:23)
at com.databricks.logging.UsageLogging.$anonfun$withAttributionContext$1(UsageLogging.scala:238)
at scala.util.DynamicVariable.withValue(DynamicVariable.scala:62)
at com.databricks.logging.UsageLogging.withAttributionContext(UsageLogging.scala:233)
at com.databricks.logging.UsageLogging.withAttributionContext$(UsageLogging.scala:230)
at com.databricks.threading.NamedExecutor.withAttributionContext(NamedExecutor.scala:265)
at com.databricks.threading.NamedExecutor$$anon$2.run(NamedExecutor.scala:335)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1149)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:624)
at java.lang.Thread.run(Thread.java:748)回答 2
Stack Overflow用户
回答已采纳
发布于 2020-06-11 16:15:13
我不确定成本的影响,但是在集群上启用自动缩放选项并增加Max Worker会怎么样呢?此外,您还可以尝试更改Worker类型,以获得更好的资源
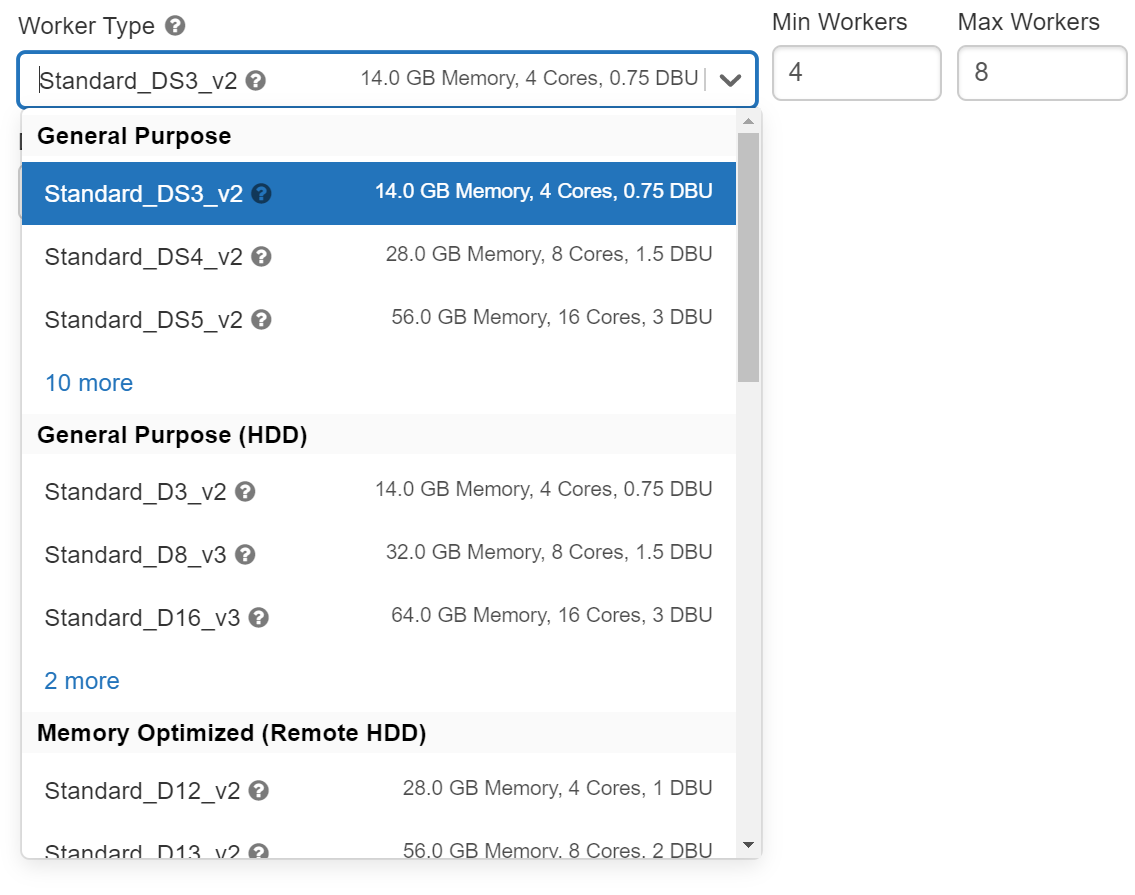
Stack Overflow用户
发布于 2022-01-12 01:30:13
只是为了其他面临类似问题的人。
在我的情况下,有时在数据库记事本的一个单元中有多个火花时也会发生同样的错误。
令人惊讶的是,在发生错误的代码之前将拆分为单元格,或者简单地在那里插入time.sleep(5)。但是我不知道它为什么会起作用..。
例如:
df1.count() # some Spark action
# split the cell or insert `time.sleep(5)` here
pipeline.fit(df1) # another Spark action where the error happened页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62275197
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号