
ER政府统计图表
我对数据库的设计还很陌生,我正在努力实践一个小国的现有政府统计数据。我已经找到了近100个表,它们存储了特定区域收集的特定年份和月份的信息。有些表格每月更新,另一些表格每年更新一次。我相信这意味着在每个表中,都会有一个由年份和月份组成的自然复合PK,或者简单地说是由一年组成的PK。
ER图
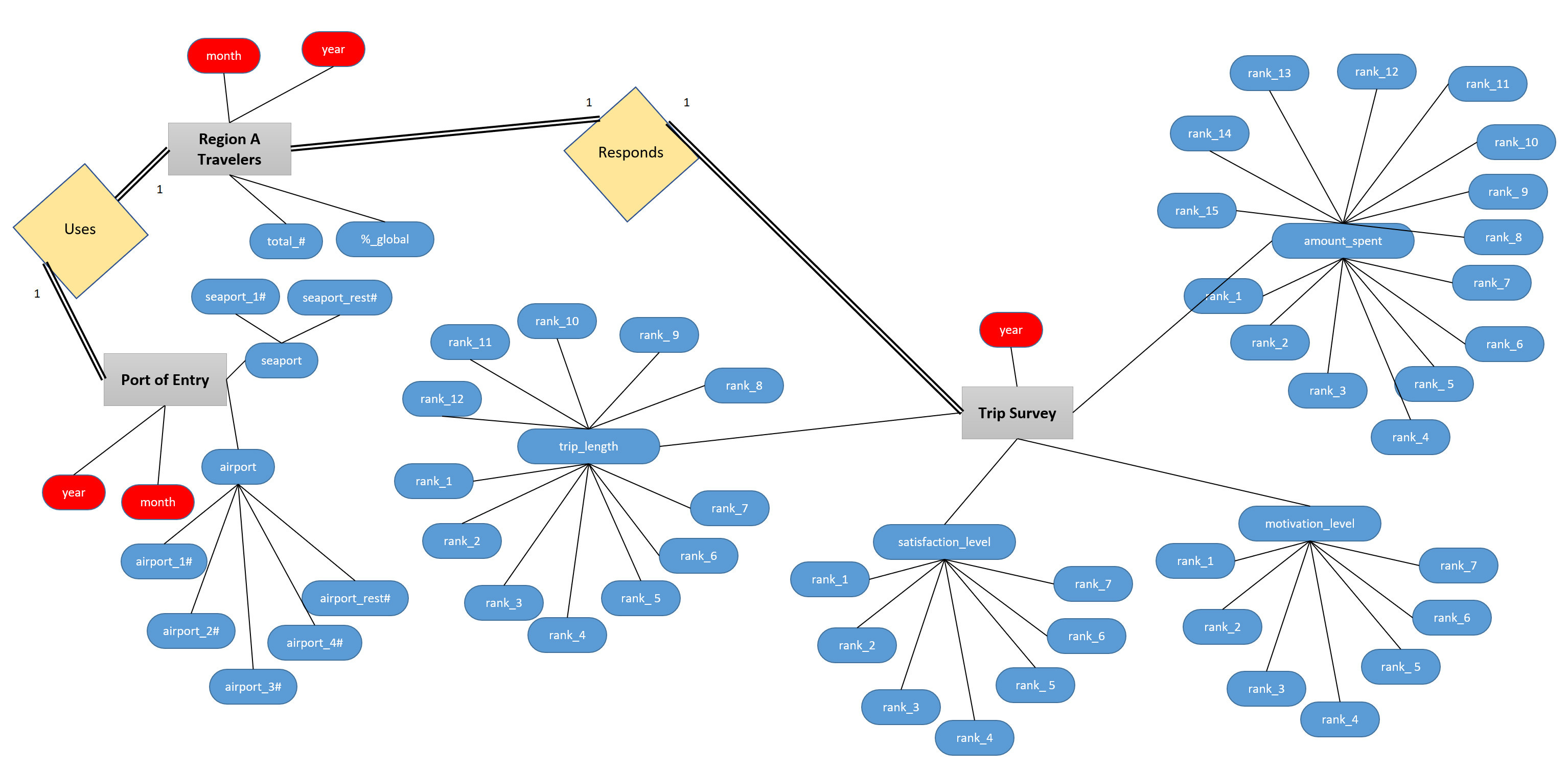
在上面的图像中,Trip调查的每个父属性代表了我从研究区域的公共数据库中收集到的许多数据表之一(例如satisfaction_level、motivation_level、amount_spent都代表了对同一人群的不同调查)。把所有的表格合并成一个表格(例如旅行调查)是否有意义?
我不确定我的关系是否准确(完全和部分参与)。我的目标是能够查询数据,找出相关点,并对未来进行预测。随着时间的推移,我想尝试把所有的表连接起来。
所收集的调查可以涵盖几乎任何主题,但共同的线索是,它们代表了一个时刻,无论是每月或每年。最后,我想增加一张表,列出一些重要的政治事件,这些事件可能会从趋势中反映出异常值。
结果:2018年,当激励水平较低时,支出也有所下降,停留时间相对于“n”期更短。
作为一个新手,任何和所有的帮助都是非常感谢的。
谢谢
回答 1
Stack Overflow用户
发布于 2020-06-17 11:25:05
简化简化。
从一个表开始,至少要理解一些列。将其加载到一些dbms中(选择一个具有地理空间功能和窗口功能的数据库管理系统,稍后您可能会想要它们: MariaDB、MySQL和PostreSQL的最新版本是很好的选择)。导入你的桌子。这可能是一个痛在axx颈部得到正确,但尽你最大的努力,它是正确的。
启动时不要担心主键或唯一索引。你只是在探索数据,而不是建立数据。不要担心购买或租用服务器:大多数笔记本电脑都能很好地处理这种探索。
选择一个客户端程序来保存您输入的查询的历史记录。HeidiSQL是一个不错的选择。Jetbrains相对较新的Datagrip值得一看。避免使用Microsoft的:没有历史记录功能。(您通常希望回到几个小时或几天前在探索时尝试过的东西,因此查询历史特性是至关重要的。)
然后摆弄查询,特别是聚合.例如:
SELECT COUNT(*), year, origin, destination
FROM trip
GROUP BY year, origin, destination;寻找你能从一张桌子上收集到的有趣的东西。掌握它的诀窍。然后向第一个表中添加另一个可以轻松成为JOINed的表。重复你的探索。
这应该能让你开始。一旦您开始理解您的数据集,您就可以开始对内容进行排序,计算出五等份数据,以及所有这些。
而且,当您必须更新或增强您的数据而不重新加载它时,您将需要各种主键/唯一键。那是你的未来。
https://stackoverflow.com/questions/62423425
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号