
Scikit-用Python学习更新
Scikit-用Python学习更新
提问于 2020-06-22 02:49:56
在提出问题之前,我先做一个介绍。但是,下面的代码并没有出现任何错误,理论上,算法应该是图2,但是图1。我在网上找到了一个类似于我的算法,但是也出现了同样的问题。我还注意到,库正在更新,而且每次都会更好。我比较了LinearRegression花型的错误分类样本,以前(我不记得版本)有8或7种,而最近的错误分类样本是1。
问题1:是否需要对代码进行任何更改才能获得图2?如果答案是否定的,那么图1的解释是什么?如果答案是肯定的,你应该修改什么,为什么?
问题2:如何才能看到库更新,特别是scikit学习算法?
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
iris = datasets.load_iris()
X = iris.data[:, [2, 3]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=0)
sc= StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
lr=LogisticRegression(C=100.0, random_state=1)
lr.fit(X_train_std,y_train)
weights, params = [], []
for c in np.arange(-5, 5):
lr = LogisticRegression(C=10.**c, random_state=1)
lr.fit(X_train_std, y_train)
weights.append(lr.coef_[1])
params.append(10.**c)
weights = np.array(weights)
plt.plot(params, weights[:, 0], color='blue', marker='x', label='petal length')
plt.plot(params, weights[:, 1], color='green', marker='o', label='petal width')
plt.ylabel('weight coefficient')
plt.xlabel('C')
plt.legend(loc='right')
plt.xscale('log')
plt.show()
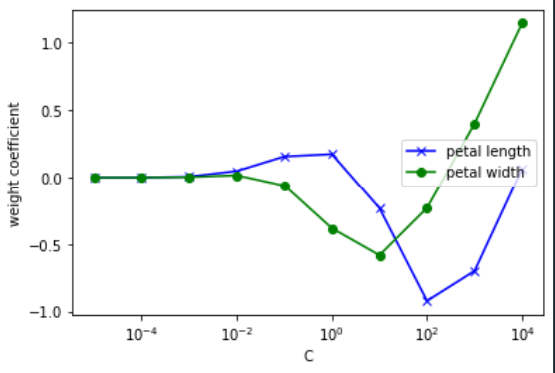
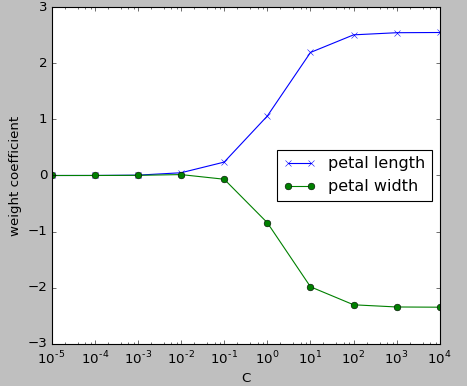
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-06-22 04:17:58
这对我起了作用:
lr = LogisticRegression(C=10.**c, random_state=1, multi_class='ovr')multi_class是在最新发布的scikit-learn中更改默认值的参数之一。(另一个参数是solver)。出于某种原因,将其转化为二进制问题解决了这个问题,但对于所发生的事情却没有太多的线索。:)
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62506761
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号