
PCA-LDA分析-R
在本例(https://gist.github.com/thigm85/8424654)中,在虹膜数据集上对LDA进行了检验。我怎样才能对PCA结果(PCA- LDA )做LDA?
代码:
require(MASS)
require(ggplot2)
require(scales)
require(gridExtra)
pca <- prcomp(iris[,-5],
center = TRUE,
scale. = TRUE)
prop.pca = pca$sdev^2/sum(pca$sdev^2)
lda <- lda(Species ~ .,
iris,
prior = c(1,1,1)/3)
prop.lda = lda$svd^2/sum(lda$svd^2)
plda <- predict(object = lda,
newdata = iris)
dataset = data.frame(species = iris[,"Species"],
pca = pca$x, lda = plda$x)
p1 <- ggplot(dataset) + geom_point(aes(lda.LD1, lda.LD2, colour = species, shape = species), size = 2.5) +
labs(x = paste("LD1 (", percent(prop.lda[1]), ")", sep=""),
y = paste("LD2 (", percent(prop.lda[2]), ")", sep=""))
p2 <- ggplot(dataset) + geom_point(aes(pca.PC1, pca.PC2, colour = species, shape = species), size = 2.5) +
labs(x = paste("PC1 (", percent(prop.pca[1]), ")", sep=""),
y = paste("PC2 (", percent(prop.pca[2]), ")", sep=""))
grid.arrange(p1, p2)回答 4
Stack Overflow用户
发布于 2020-06-25 11:08:01
通常你做PCA-LDA来减少数据的尺寸,然后再进行PCA。理想情况下,您可以决定第一个k个组件不受PCA的影响。在使用虹膜的例子中,我们使用前两个组件,否则它看起来将与不使用PCA的情况大致相同。
试着这样做:
pcdata = data.frame(pca$x[,1:2],Species=iris$Species)
pc_lda <- lda(Species ~ .,data=pcdata , prior = c(1,1,1)/3)
prop_pc_lda = pc_lda$svd^2/sum(pc_lda$svd^2)
pc_plda <- predict(object = pc_lda,newdata = pcdata)
dataset = data.frame(species = iris[,"Species"],pc_plda$x)
p3 <- ggplot(dataset) + geom_point(aes(LD1, LD2, colour = species, shape = species), size = 2.5) +
labs(x = paste("LD1 (", percent(prop_pc_lda[1]), ")", sep=""),
y = paste("LD2 (", percent(prop_pc_lda[2]), ")", sep=""))
print(p3)
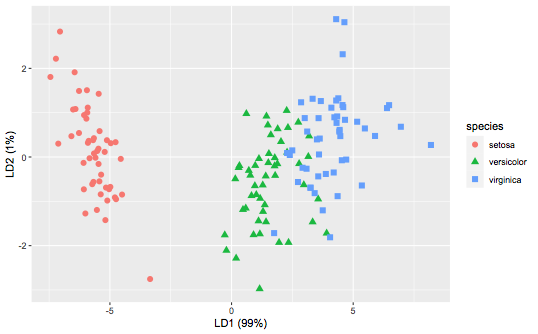
您不会在这里看到太多的差别,因为PCA的前2个组件捕获了虹膜数据集中的大部分方差。
Stack Overflow用户
发布于 2020-06-25 11:04:54
这非常简单,将lda应用于princomp在问题代码中返回的主组件坐标。
pca_lda <- lda(pca$x, grouping = iris$Species)现在的问题是对每种对象类型使用predict方法来获得分类的精确性。
pred_pca_lda <- predict(lda0, predict(pca, iris))
accuracy_lda <- mean(plda$class == iris$Species)
accuracy_pca_lda <- mean(pred_pca_lda$class == iris$Species)
accuracy_lda
#[1] 0.98
accuracy_pca_lda
#[1] 0.98Stack Overflow用户
发布于 2021-09-11 03:15:49
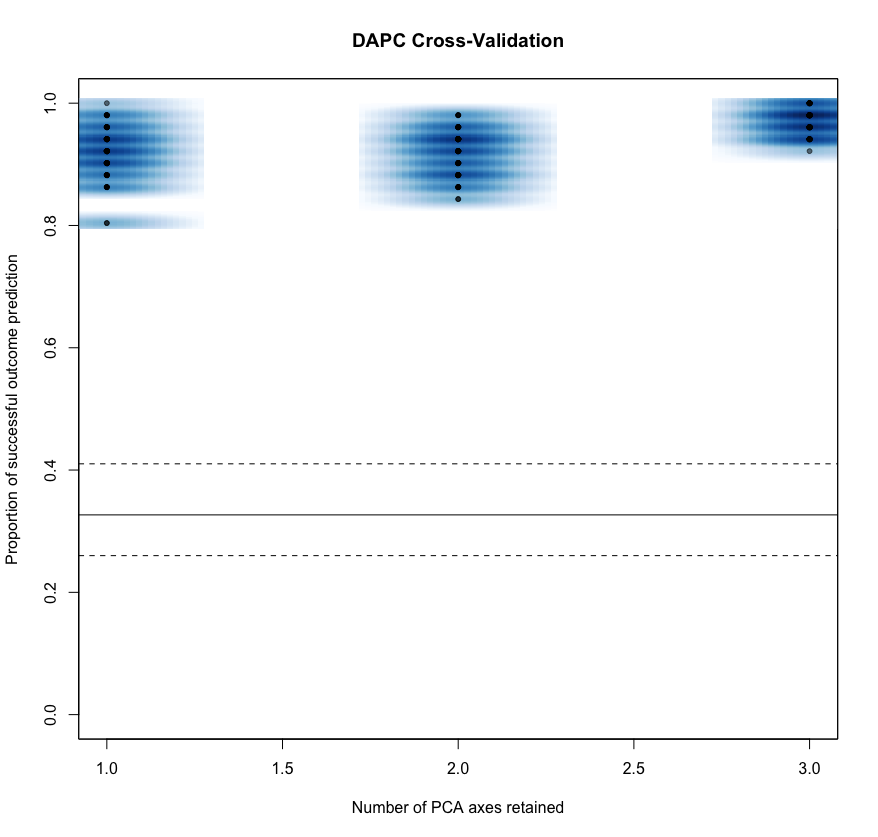
对于PCA-LDA (又称主成分判别分析,DAPC),在数据不拟合和过拟合之间找到最佳的折衷方案是非常重要的。这是非常棘手的,特别是对于高维数据(许多变量=列)。在这种情况下,交叉验证将成为机器学习中的一个问题.唯一要调优的超参数是保留的PC数。
adegenet软件包提供了PCA的方便实现(主要考虑到遗传数据,但它可以用于任何类型的数据)。xvalDapc函数适用于数据的引导子集(training.set参数)上的n.rep LDA模型,用于保留PC的所有指示数(n.pca参数)。使用指定的性能度量(result参数),它在所有重复中找到关联最小的均方误差( n.pca )。
用于DAPC的调优n.pca
library(adegenet)
# center and scale data to unit variance
iris.s <- scale(iris[,1:4])
# tune PCA-LDA / DAPC hyperparameter (n.pca)
d.dapc <- xvalDapc(x = iris.s, grp = iris[,5],
scale = FALSE, center = TRUE, result = "groupMean",
training.set = 2/3, n.pca = 1:3, n.rep = 100)
(n.pca <- as.numeric(d.dapc$`Number of PCs Achieving Lowest MSE`))请注意,缩放在这里是有意义的,因为花瓣和萼片比宽得多。对非比例数据的分析将导致PC组件沉重地负载花瓣和萼片长度(由于它们的较大的方差),尽管花瓣宽度是一个重要的区别特征(见下面的图)。
最后提出的DAPC模型d.dapc$DAPC适合于完整的训练数据,使用的最优n.pca为3。
使用交叉验证确定了最优n.pca之后,用一些附加结果(原始变量$var.load的加载)重新拟合模型的一种快速方法是使用dapc函数(由xvalDapc使用):
dd.dapc <- dapc(x = iris.s, grp = iris[,5], n.pca = n.pca, n.da = 2,
scale = FALSE, center = TRUE, var.loadings = TRUE)dapc对象类包含各种插槽,其中最重要的是:
- DAPC评分(
$ind.var) - LD函数(
$var.load)的原始变量的负载或系数 - 每个变量对LD函数(
$var.contr)的绝对贡献 - 特征值,用于计算%解释方差(
$eig)
计算%解释方差
> (expl_var <- dd.dapc$eig / sum(dd.dapc$eig))
[1] 0.991500694 0.008499306dapc 和 prcomp / lda的比较
iris.pca <- prcomp(iris.s, center = TRUE, scale. = FALSE)
iris.lda <- lda(x = iris.pca$x[,1:n.pca], grouping = iris[,5])
scores.own <- predict(iris.lda)$x
# check conformity
scores.dapc <- dd.dapc$ind.coord
all.equal(unname(scores.own), unname(scores.dapc)) # it's the same!
[1] TRUEVisualization
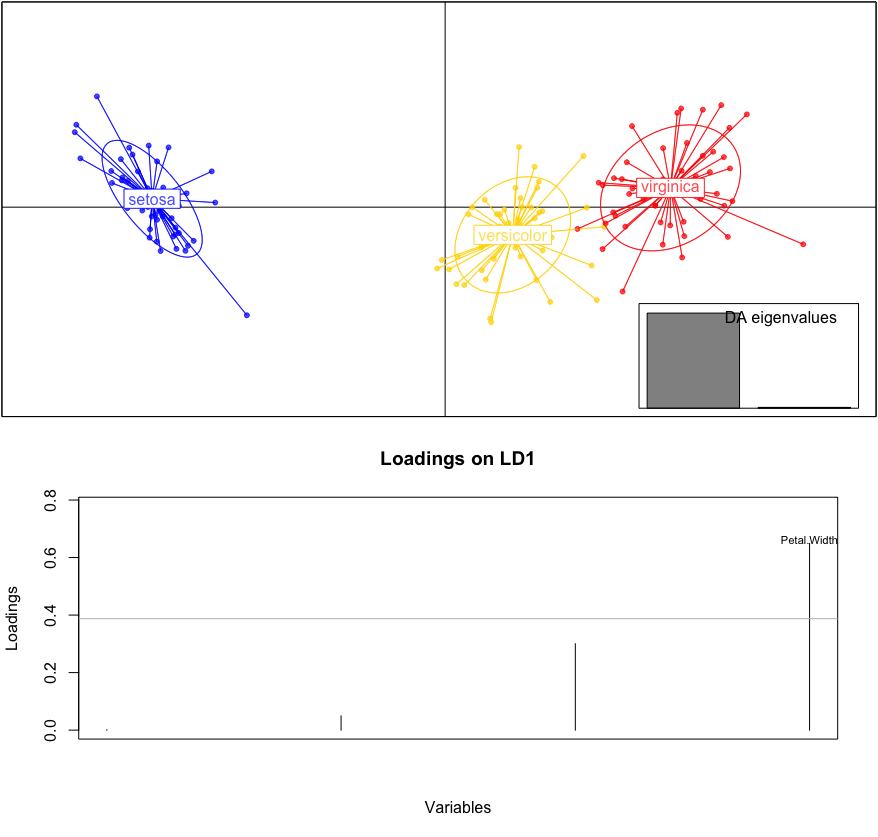
par(mfrow=c(2,1))
scatter(dd.dapc)
loadingplot(dd.dapc$var.contr, axis = 1, main = "Loadings on LD1")
par(mfrow=c(1,1))
https://stackoverflow.com/questions/62573178
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号