
为什么“使用比嵌入层后面的层中的单位数更多的嵌入维度是浪费的”
引用自“手工机器学习与Scikit-学习,Keras,和TensorFlow,第二版”:
一次热编码,然后是密集层(没有激活函数,没有偏见),相当于嵌入层。然而,嵌入层使用的计算量要少得多(当嵌入矩阵的大小增大时,性能差异变得明显)。稠密层的权重矩阵起着嵌入矩阵的作用。例如,使用一个大小为20的热向量和一个10个单元的密集层相当于使用一个嵌入层与input_dim=20和output_dim=10. ,因此,使用比嵌入层后面的层中的单位数更多的嵌入维将是浪费的。
为什么“使用更多的嵌入维度比嵌入层后面的单元数更浪费”?
回答 1
Stack Overflow用户
发布于 2021-06-29 18:51:57
我也偶然发现了同样的问题,下面是我想出的一些问题。如果有什么错误,很抱歉。
首先,考虑一个简单的(线性)密集层,它包含input_dim=a,output_dim=c,让我们称之为d12。暂时忽视偏见。
a --d12--> c
c_x = d12.weight * a_x可以将这个致密层分成2个致密层,第一个(d1)有input_dim=a,output_dim=b,第二个(d2)有input_dim=b,output_dim=c。
a --d1--> b --d2--> c
b_x = d1.weight * a_x
c_x = d2.weight * b_x
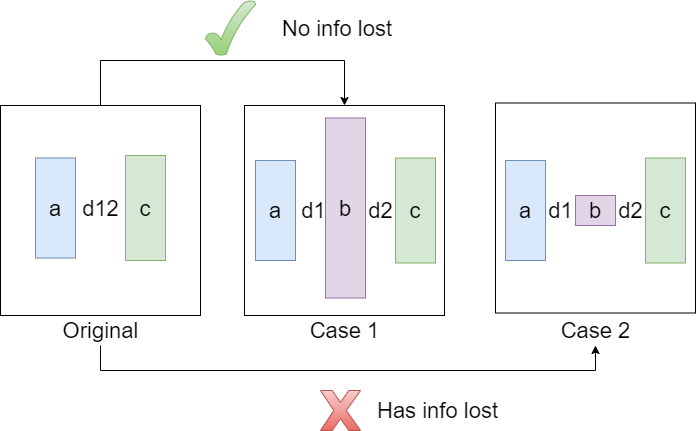
(d12.weight = d2.weight * d1.weight)这里的问题是:拆分是否减少了信息量。在这里我们有两个案例:
a*c <= a*b + b*c(即d12的参数小于d1+d2):没有丢失信息,只引入附加的computation.a*c > a*b + b*c(即d12比d1+d2具有更多的参数):一些信息丢失了。基本上,b成为了一个瓶颈,就像编码器-解码器结构一样。
。
因此,如果在一个网络中,对于2个线性密集层,可以在不丢失信息的情况下组合成一个线性密集层,则中间维(b)大于输出维数(c)。
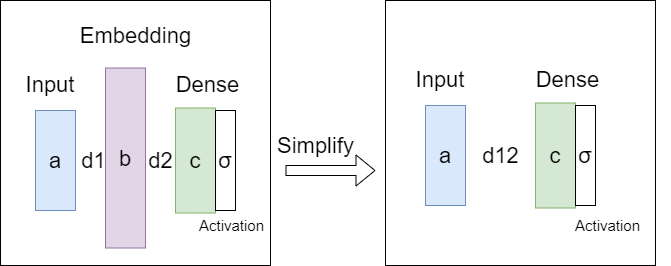
嵌入层本质上是具有input_dim=vocab_len、output_dim=embedding_dim、activation=“线性”的(线性)密集层。因此,如果嵌入层的output_dim大于其后面的密集层,则可以有效地简化该嵌入层。
https://stackoverflow.com/questions/62666570
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号