
Excel:在多个ID中按日期排序
Excel:在多个ID中按日期排序
提问于 2020-07-07 21:08:16
我有一个庞大的流行病学数据集,包含有病理报告和临床信息的登记数据。为了从一个文件中获取所有信息,我将多个文件合并到一个主文件中。每个病人都有一个唯一的身份证号码。每个病人都可以有几个报告,因此相同的ID号可以在ID列中重复几次。对于每一个ID条目=新行(=病理学或临床报告),都有报告样本/信息的日期。
我的目标是能够阅读所有的病理/临床信息,为一个特定的ID在一排。
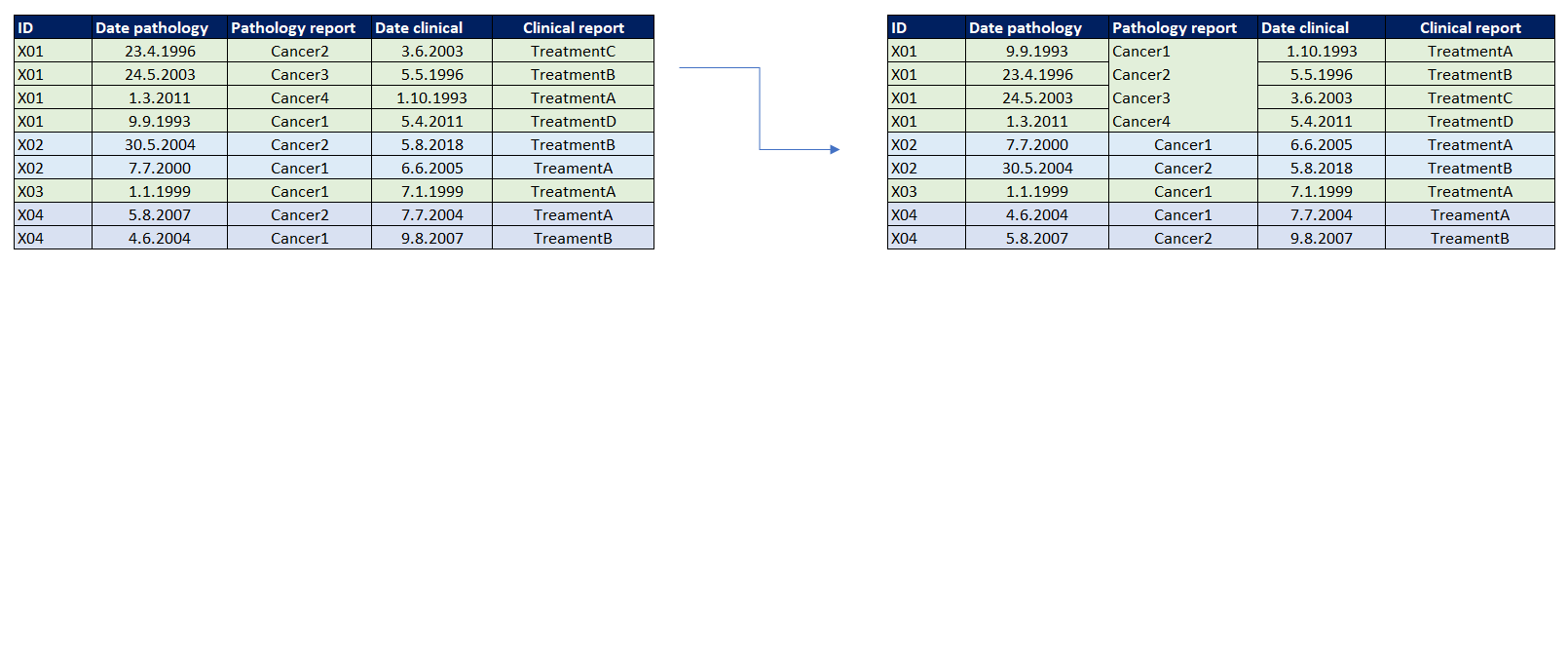
通过对ID进行排序,我可以清楚地了解输入的每个ID的数量。当有几个带有相同ID的报告=多个行时,就会出现这个问题,因为这个报告中的日期与多个ID=行的日期不匹配。数据来源于病理学(样本日期、回答日期、临床资料日期等)。一名病人的病理和临床数据不一定要在当天准确匹配,但仍要在合理的时间框架内,例如在1-2个月内。最好用一个例子来说明这一点。
我想对列进行排序,以便从特定的行匹配到一起。我相信这是有办法的,但我想不出来。
提前感谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-07-07 22:44:28
当两个单独的表合并为一个表时,似乎出现了不匹配记录的问题。为了解决这个问题,您可以选择以下几个选项:
- 重新进行合并,但加强了表的连接方式。
- 不只是基于
ID进行合并,而是查看是否还有其他字段可以轻松地连接记录,比如medical record #、case #或event #,并根据这个新字段和ID合并表。这将是最强大的解决方案,但是,只有当您能够找到上述字段来增强link.
- 不只是基于
时,它才能工作。
- 一个单独的解决方案是首先根据日期对原始表进行排序,以便它们匹配起来,然后将它们重新合并在一起。从理论上讲,这应该可以解决您的问题,正如我目前假设的那样,在匹配两个独立的表时,它从两个表中获取了患者的第一个实例,并将它们匹配在一起。这可以通过检查合并查询来确认,并查看不匹配的记录是否与原始表中显示的顺序相同。这并不完美,因为它依赖于记录病理日期之间的临床日期,所以我会谨慎行事。为了解决您对多行ID丢失的关注,这不重要,因为在合并后的最终结果中,您可以根据ID进行排序,但是您可以通过选择数据并进入 data ->
Sort->Add Level来添加多个级别的排序。您可以更改数据排序的顺序(首先按ID排序,然后按ID排序)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62783963
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号