
抓取WordPress评论
我只是在学习R编程。在练习中,我想对一个似乎已经停止使用的WordPress插件这里进行评论。
我首先指定URL
> url <- 'https://wordpress.org/plugins/demo-data-creator/#reviews'从URL中抓取HTML内容
> url <- read_html('https://wordpress.org/plugins/demo-data-creator/#reviews')使用ID标记提取每个评审的标题
> reviews <- html_nodes(url, 'h3.review-title')去掉HTML标记,只留下标题的内容
> titletext <- html_text(reviews)打印被刮过的书名
> head(titletext)
> [1] "Good for development"
> [2] "Used it for creating test users"
> [3] "Excelent! negative comments come from people who doesn't read!"
> [4] "Thanks"
> [5] "Does EXACTLY what it says it will – thanks! Very Handy"
> [6] "Dangerous plugin" 我对评论的内容重复同样的话。
> reviewcontent <- html_nodes(url, 'div.review-content')
> reviewtext <- html_text(reviewcontent)打印出来
> head(reviewcontent)
> {xml_nodeset (6)} [1] <div class="review-content">Good and handy tool
> for deve ... [2] <div class="review-content">This plugin came in very
> han ... [3] <div class="review-content">Does exactly what it offers!
> ... [4] <div class="review-content">Thanks</div> [5] <div
> class="review-content">Very handy for a test system ... [6] <div
> class="review-content">I have to agree with viesli ...然而,我意识到它并没有刮掉所有的评论,因为有更多的这里
是否有一种方法可以告诉R检查列出的每个评论,以提取标题和审阅内容,并可能填充到一个表中?
回答 1
Stack Overflow用户
发布于 2020-07-10 10:53:34
您可以使用相同的方法从第二个链接中提取评论。的主要区别是是,每个评论的内容都在它自己的页面中。因此,您需要两个步骤:
- 从主页中提取审阅页面URL的列表。
- 对于每个 URL,获取页面,提取评论的标题和内容。
对于步骤1,它与您已经做过的非常相似,只不过现在您正在尝试提取审查页面的URL。如果检查该页面,您将看到这些链接(<a>元素)具有CSS类bbp-topic-permalink。
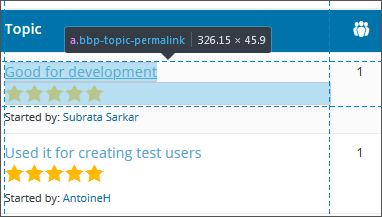
因此,我们可以使用以下方法提取它们:
links <- html_nodes(page, css='a.bbp-topic-permalink')现在,我们不需要标记的文本部分,而是href属性值(链接指向的位置)。我们可以用
reviewurls <- html_attr(links, 'href')对于步骤2,我们将循环遍历reviewurls列表,对于每个列表,使用read_html获取页面,使用html_node和html_text提取标题和内容,然后将它们添加到表/矩阵/data.framework中。
可以使用以下方法完成循环:
for (u in reviewurls) {
}在循环中,u是保存当前审查URL的变量。我们将使用read_html读取页面,然后提取标题和内容。
检查检查页面时,标题位于带有CSS类page-title的<h1>标记中。同样重要的是,评审的thThe内容在具有CSS类bbp-topic-content的<div>中。
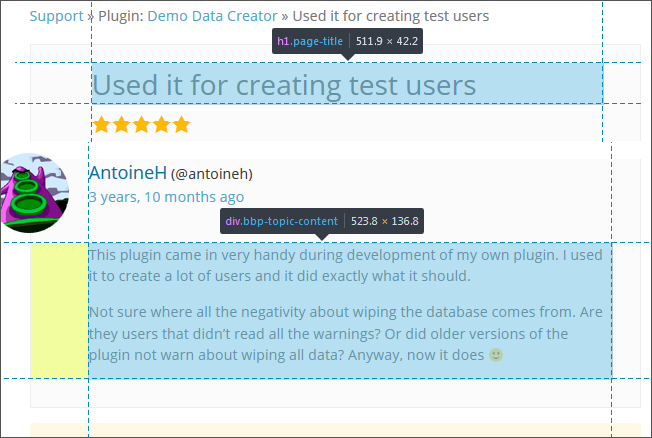
因此,在循环中,您可以这样做:
page = read_html(u)
reviewT = html_text(html_node(page, css='h1.page-title'))
reviewC = html_text(html_node(page, css='div.bbp-topic-content'))现在,您将拥有该特定评论的标题和内容。您可以将它们添加到列表中,以便在循环结束时,您将拥有所有评论的标题和内容。
最后的代码如下所示:
url <- 'https://wordpress.org/support/plugin/demo-data-creator/reviews/'
page <- read_html(url)
links <- html_nodes(page, css='a.bbp-topic-permalink')
reviewurls <- html_attr(links, 'href')
# Two empty lists, to be populated inside the loop
titles = c()
contents = c()
for (u in reviewurls) {
page = read_html(u)
reviewT = html_text(html_node(page, css='h1.page-title'))
reviewC = html_text(html_node(page, css='div.bbp-topic-content'))
titles = c(titles, reviewT)
contents = c(contents, reviewC)
}一旦完成,你就会得到:
> length(titles)
[1] 21
> head(titles)
[1] "Good for development"
[2] "Used it for creating test users"
[3] "Excelent! negative comments come from people who doesn't read!"
...
> head(contents)
[1] "\n\n\t\t\t\t\n\t\t\t\tGood and handy tool for development.\n\n\n\n\t\tThis topic was modified 2 years, 10 months ago by Subrata Sarkar.\n\t\n\n"
[2] "\n\n\t\t\t\t\n\t\t\t\tThis plugin came in very handy during development of my own plugin. I used it to create a lot of users and it did exactly what it should.\nNot sure where all the negativity about wiping the database comes from. Are they users that didn’t read all the warnings? Or did older versions of the plugin not warn about wiping all data? Anyway, now it does \U0001f642\n\n\t\t\t\t\n\t\t\t"
[3] "\n\n\t\t\t\t\n\t\t\t\tDoes exactly what it offers! Nothing less.\nPeople complaining is too lazy to read the SEVERAL warnings about the usage of this plugin.\n\n\t\t\t\t\n\t\t\t"
...https://stackoverflow.com/questions/62823050
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号