
我做错了什么?无法执行一行代码。Python / Data Science \ Big Mart销售数据集
我做错了什么?无法执行一行代码。Python / Data Science \ Big Mart销售数据集
提问于 2020-07-12 04:02:17
我一直在努力学习分析大商场的销售数据集。在NaN列中有一些Item_Weight值。因此,我想通过从包含pivot_table的Item_Identifier as Index和Item_Weight中找到值来更新这些值。这是图像
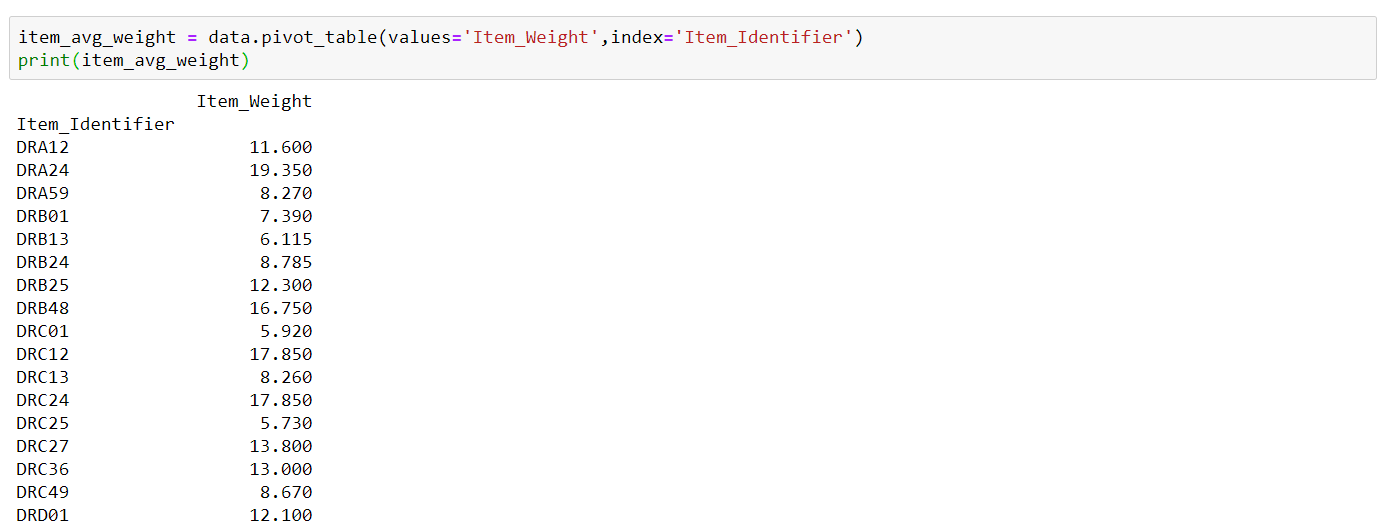
cdata['Item_Weight'] = cdata[['Item_Weight','Item_Identifier']].apply(lambda x: item_avg_weight.loc[x[1],'Item_Weight'] if pd.isnull(x[0]) else x[1]).astype(float)但是,当我运行上面的代码行时,我会得到一个错误
我无法理解为什么我会得到这个错误。
指向数据集的链接:https://www.kaggle.com/brijbhushannanda1979/bigmart-sales-data/data
编辑1
错误日志
ValueError Traceback (most recent call last)
<ipython-input-158-7ecf8cf7385f> in <module>
----> 1 cdata['Item_Weight'] = cdata[['Item_Weight','Item_Identifier']].apply(lambda x: item_avg_weight.loc[x[1],'Item_Weight'] if pd.isnull(x[0]) else x[1]).astype(float)
~\Anaconda3\lib\site-packages\pandas\core\generic.py in astype(self, dtype, copy, errors, **kwargs)
5689 # else, only a single dtype is given
5690 new_data = self._data.astype(dtype=dtype, copy=copy, errors=errors,
-> 5691 **kwargs)
5692 return self._constructor(new_data).__finalize__(self)
5693
~\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in astype(self, dtype, **kwargs)
529
530 def astype(self, dtype, **kwargs):
--> 531 return self.apply('astype', dtype=dtype, **kwargs)
532
533 def convert(self, **kwargs):
~\Anaconda3\lib\site-packages\pandas\core\internals\managers.py in apply(self, f, axes, filter, do_integrity_check, consolidate, **kwargs)
393 copy=align_copy)
394
--> 395 applied = getattr(b, f)(**kwargs)
396 result_blocks = _extend_blocks(applied, result_blocks)
397
~\Anaconda3\lib\site-packages\pandas\core\internals\blocks.py in astype(self, dtype, copy, errors, values, **kwargs)
532 def astype(self, dtype, copy=False, errors='raise', values=None, **kwargs):
533 return self._astype(dtype, copy=copy, errors=errors, values=values,
--> 534 **kwargs)
535
536 def _astype(self, dtype, copy=False, errors='raise', values=None,
~\Anaconda3\lib\site-packages\pandas\core\internals\blocks.py in _astype(self, dtype, copy, errors, values, **kwargs)
631
632 # _astype_nansafe works fine with 1-d only
--> 633 values = astype_nansafe(values.ravel(), dtype, copy=True)
634
635 # TODO(extension)
~\Anaconda3\lib\site-packages\pandas\core\dtypes\cast.py in astype_nansafe(arr, dtype, copy, skipna)
700 if copy or is_object_dtype(arr) or is_object_dtype(dtype):
701 # Explicit copy, or required since NumPy can't view from / to object.
--> 702 return arr.astype(dtype, copy=True)
703
704 return arr.view(dtype)
ValueError: could not convert string to float: 'DRC01'我需要什么?
我想更新cdata DataFrame,以便Item_Weight列没有任何NaN值。我想借助一个枢轴表,即item_avg_weight,它包含了Item_Identifier的项目权重。
编辑2
有关数据的信息
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 14204 entries, 0 to 14203
Data columns (total 13 columns):
Item_Fat_Content 14204 non-null object
Item_Identifier 14204 non-null object
Item_MRP 14204 non-null float64
Item_Outlet_Sales 8523 non-null float64
Item_Type 14204 non-null object
Item_Visibility 14204 non-null float64
Item_Weight 11765 non-null float64
Outlet_Establishment_Year 14204 non-null int64
Outlet_Identifier 14204 non-null object
Outlet_Location_Type 14204 non-null object
Outlet_Size 10188 non-null object
Outlet_Type 14204 non-null object
source 14204 non-null object
dtypes: float64(4), int64(1), object(8)
memory usage: 1.4+ MB回答 1
Stack Overflow用户
发布于 2020-07-12 06:28:42
我的理解是,对于Item_Identifier
- This,您想要
fillna,基于follows
- There中每个组的
mean可以使用groupby和groupby.apply来完成,因为groupby.apply应该是两个文件,所以为每个文件
- 创建一个数据文件
NaN值可以被填充,或者像df_test.dropna(inplace=True)
那样被删除
import pandas as pd
# create two dataframes
df_test = pd.read_csv('datasets_9961_14084_Test.csv')
df_train = pd.read_csv('datasets_9961_14084_Train.csv')
# fill the NaN values in Item_Weight with the mean of their repective Item_Identifier group
df_test.Item_Weight = df_test.groupby('Item_Identifier')['Item_Weight'].apply(lambda x: x.fillna(x.mean()))
df_train.Item_Weight = df_train.groupby('Item_Identifier')['Item_Weight'].apply(lambda x: x.fillna(x.mean()))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/62856937
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号