
如何重新安排传奇故事的情节和华丽?
我有一个很简单的问题,但我不知道如何解决它:我正在绘制利克特刻度条形图。
likert_results2 <- structure(list(Survey = c("Post survey \nN= 274", "Post survey \nN= 274",
"Post survey \nN= 274", "Post survey \nN= 274", "Post survey \nN= 274",
"Post survey \nN= 274", "Pre survey \nN= 429", "Pre survey \nN= 429",
"Pre survey \nN= 429", "Pre survey \nN= 429", "Pre survey \nN= 429",
"Pre survey \nN= 429", "Post survey \nN= 276", "Post survey \nN= 276",
"Post survey \nN= 276", "Post survey \nN= 276", "Post survey \nN= 276",
"Post survey \nN= 276", "Pre survey \nN= 428", "Pre survey \nN= 428",
"Pre survey \nN= 428", "Pre survey \nN= 428", "Pre survey \nN= 428",
"Pre survey \nN= 428"), Response = c("agree", "disagree", "neither agree nor disagree",
"somewhat agree", "somewhat disagree", "strongly agree", "agree",
"disagree", "neither agree nor disagree", "somewhat agree", "somewhat disagree",
"strongly agree", "agree", "disagree", "neither agree nor disagree",
"somewhat agree", "somewhat disagree", "strongly agree", "agree",
"disagree", "neither agree nor disagree", "somewhat agree", "somewhat disagree",
"strongly agree"), Question = c("q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q1",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2",
"q2"
), prop = c(0.17, 0.21, 0.08, 0.29, 0.16, 0.09, 0.14, 0.16, 0.16,
0.3, 0.18, 0.07, 0.13, 0.21, 0.11, 0.29, 0.19, 0.07, 0.11, 0.18,
0.18, 0.28, 0.21, 0.06)), class = c("tbl_df", "tbl", "data.frame"
), row.names = c(NA, -24L))
# Create data frame with labels
prop_labels <- likert_results2 %>%
mutate(
position = case_when(
Response == "somewhat disagree" | Response == "disagree" | Response == "strongly disagree" ~ "left",
Response == "neither agree nor disagree" ~ "center",
Response == "somewhat agree" | Response == "agree" | Response == "strongly agree" ~ "right"
)
) %>%
group_by(Question, Survey, position) %>%
dplyr::summarize(.,label = sum(prop * 100)) %>%
pivot_wider(names_from = position,
values_from = label)
# Data frame with left side values
high_columns <- likert_results2 %>%
filter( Response == "strongly disagree" | Response == "disagree"| Response == "somewhat disagree" | Response == "neither agree nor disagree") %>%
mutate(prop = case_when(Response == "strongly disagree" ~ prop * 100,
Response == "disagree" ~ prop * 100,
Response == "somewhat disagree" ~ prop * 100,
Response == "neither agree nor disagree" ~ prop / 2 * 100
))
# Data frame with right side values
low_columns <- likert_results2 %>%
filter(Response == "neither agree nor disagree" | Response == "somewhat agree" | Response == "agree" | Response == "strongly agree") %>%
mutate(prop = case_when(Response == "neither agree nor disagree" ~ prop / 2 * 100,
Response == "somewhat agree" ~ prop * 100,
Response == "agree" ~ prop * 100,
Response == "strongly agree" ~ prop * 100,
))
# Define empty ggplot object
p <- ggplot() +
# Add central black line
geom_hline(yintercept = 0,
linetype="dashed",
colour ="darkgrey") +
# Add right side columns
geom_bar(
data = high_columns,
mapping = aes(x = Survey,
y = prop,
fill = Response),
position = position_stack(reverse = F),
stat = "identity"
) +
# Add left side columns
geom_bar(
data = low_columns,
mapping = aes(x = Survey,
y = -prop,
fill = Response),
position = position_stack(reverse = T),
stat = "identity"
) +
#Right side labels
geom_text(
data = prop_labels,
mapping = aes(
x = Survey,
y = -100,
label = paste(ifelse(is.na(right),0,round(right)) , "%", sep = "")),
hjust = 1,
color = "black",
size = 3
) +
# Central labels
geom_text(
data = prop_labels,
mapping = aes(
x = Survey,
y = 0,
label = paste(ifelse(is.na(center),0,round(center)) , "%", sep = "")),
hjust = 0.5,
color = "black",
size = 3
) +
# Left side labels
geom_text(
data = prop_labels,
mapping = aes(
x = Survey,
y = 100,
label = paste(ifelse(is.na(left),0,round(left)) , "%", sep = "")),
hjust = -0.2,
color = "black",
size = 3
) +
# Scale formatting
scale_y_continuous(
breaks = seq(-100, 100, 50),
limits = c(-105, 105),
labels = abs
) +
# More formatting
theme(legend.title = element_blank(),
legend.position = "right",
axis.ticks = element_blank(),
strip.background = element_rect(fill = "#F0F0F0",
color = "#F0F0F0"),
panel.background = element_blank(),
panel.border = element_rect(
colour = "#F0F0F0",
fill = NA,
size = 1.5)
) +
facet_wrap(~ Question, scales="free_y",ncol = 1) +
coord_flip() +
ylab("Percent of students") +
xlab("") +
# Change Likert labels
scale_fill_manual(name = "Response", values = c("#1E4384","#6495CF","#7278A8","#AFA690", "#E9739B","#B54461","#B1235E") ,labels=c("strongly agree","agree","somewhat agree","neither agree nor disagree","somewhat disagree","disagree","strongly disagree"))
# Print the plot
p
#plotly graph
ggplotly(p, width = 1200, height = 800) 我的问题是让传说中的物品以适当的方式订购。如果我在不使用scale_fill_manual的情况下运行代码,则图如下所示:
除了添加scale_fill_manual时的图例顺序外,一切都是正确的。
当我用scale_fill_manual指定顺序时,我得到以下结果:这确实改变了图例中的更正顺序,但没有更改带有颜色的方块:
当我快速运行时,该命令也会删除我指定的所有命令。1:https://i.stack.imgur.com/Z53nF.png 2:https://i.stack.imgur.com/QeRnw.png
{kind=link}
{kind=link}
回答 1
Stack Overflow用户
发布于 2020-07-13 01:16:49
您的代码似乎缺少了一些变量,因此我无法获得相同的图来显示您,但您的问题似乎最好使用一个示例数据框架来回答。TL;DR -使用breaks=在图例中分配密钥顺序。
您问题的答案在于了解如何使用scale_*_manual()更改图例的各个方面。
labels=使用它来更改每个图例键的外观(单词)。
当您开始设置任何其他参数时,
values=是必需的。如果提供命名向量或列表,则可以显式地为与数据关联的底层因素的每个级别分配颜色。如果您提供了一个颜色列表,它们将根据图例中标签的顺序进行分配。注意,它不是根据因子的级别来分配的。
breaks=使用此参数指示图例键出现的顺序。
下面是一个例子:
library(dplyr)
library(tidyr)
library(ggplot2)
df <- data.frame(x=1:100, Low=rnorm(100,5,1.2),Med=rnorm(100,10,2),High=rnorm(100,15,0.8))
df <- df %>% gather('Status','Values',-x)
p <- ggplot(df, aes(Status,Values)) + geom_boxplot(aes(fill=Status), alpha=0.5)
p + scale_fill_manual(values=c('red','blue','green'))
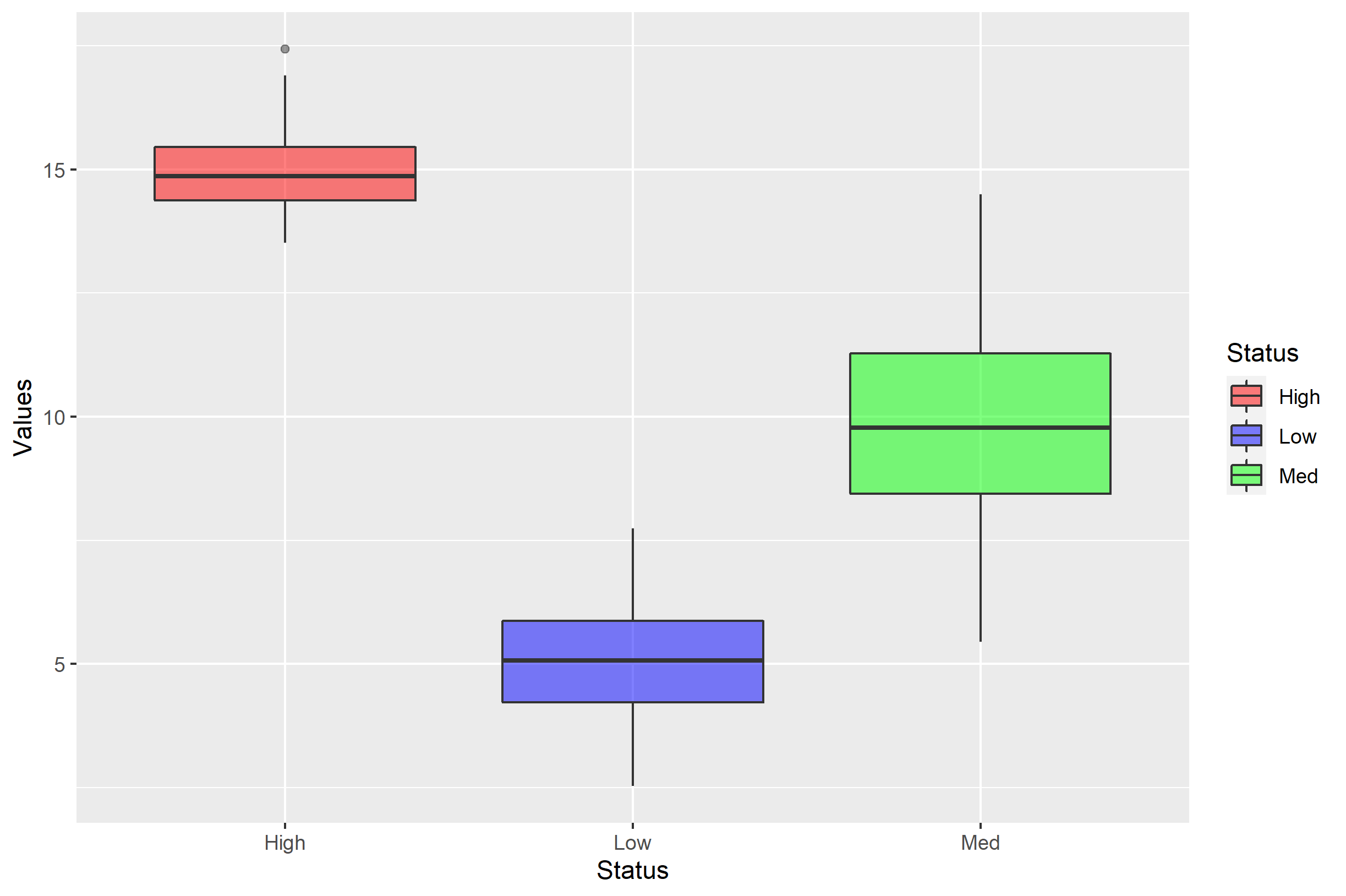
df$Status在x轴上的出现顺序由levels=在factor(df$Status)中的顺序决定。这不是你在问题中问的问题,但记住是很好的。默认情况下,这似乎是按字母顺序决定的。
图例条目也是按字母顺序排列的,但这是因为对于离散值,顺序将默认为factor(df$Status)中级别的顺序。因此,values=的未命名颜色向量是根据图例中项的顺序分配的。
注意,如果使用labels=试图将其恢复到"Low,Med,High“,会发生什么情况:
p + scale_fill_manual(labels=c('Low','Med','High'), values=c('red','blue','green'))
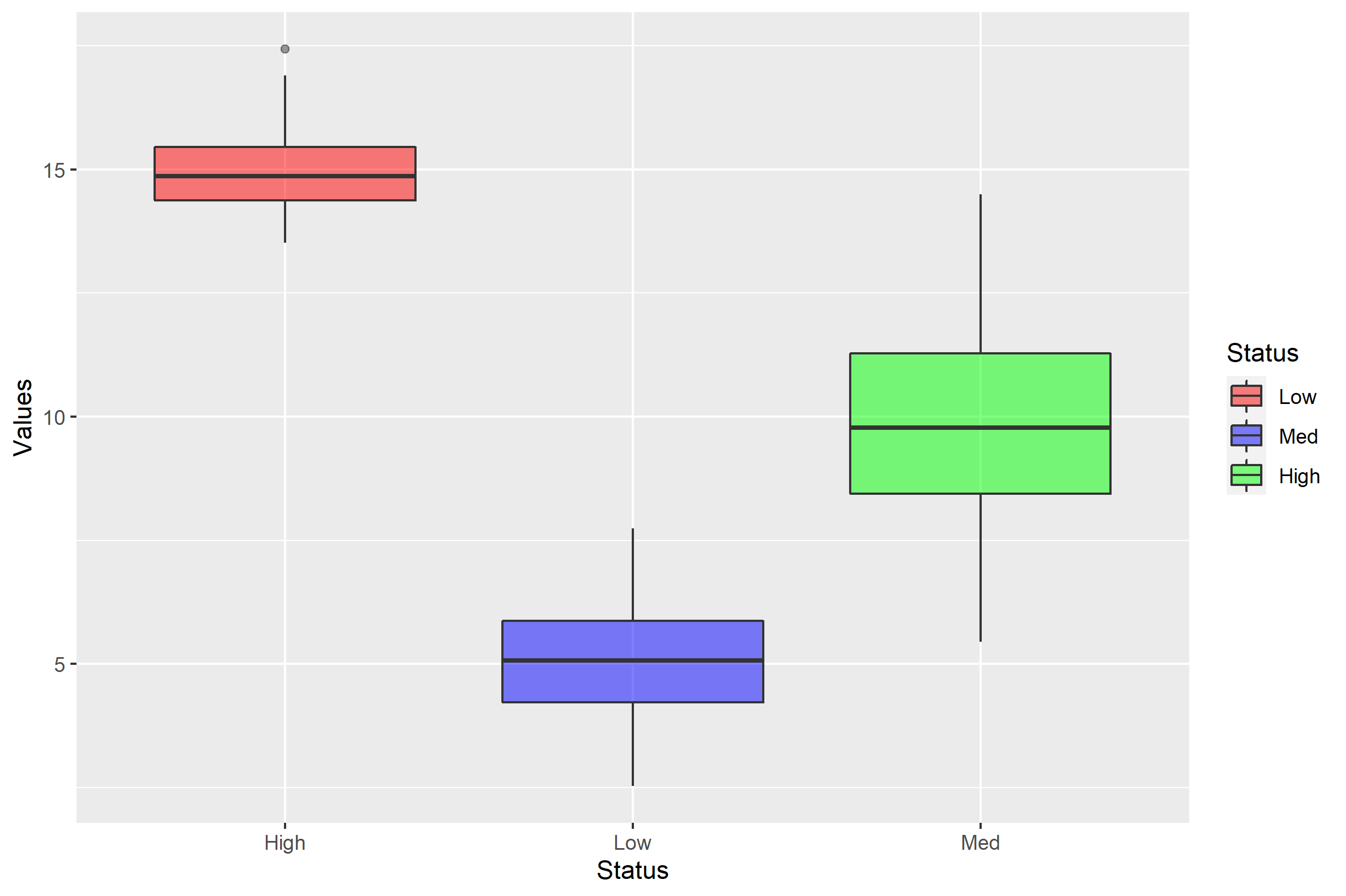
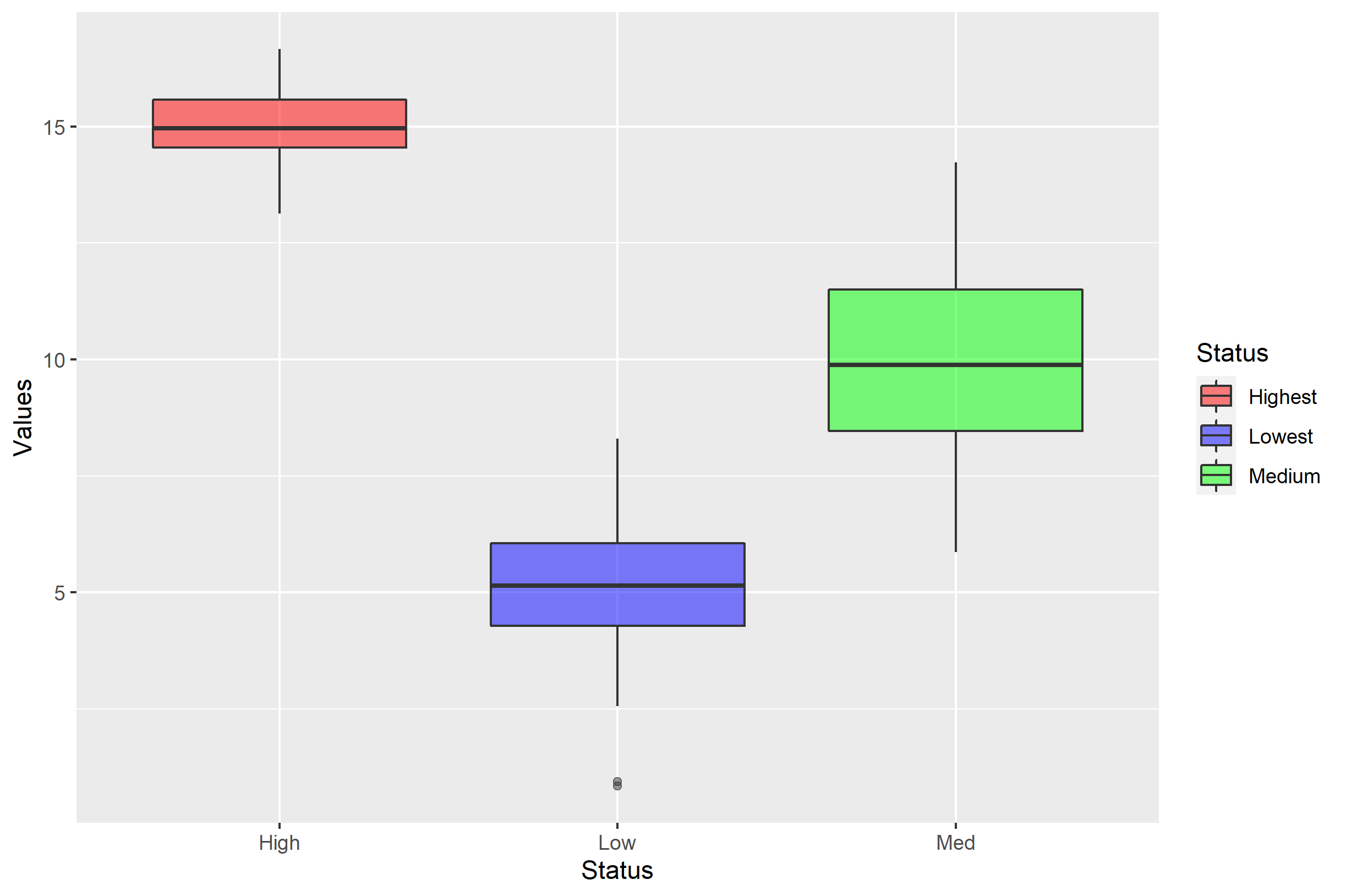
现在,您应该看到用一个简单的向量分配labels=的危险。labels=参数只是简单地重命名各个级别的标签..。但秩序并没有改变。如果我们想重命名这些级别,更好的方法是向labels=发送一个命名的向量:
p + scale_fill_manual(
labels=c('Low'='Lowest','Med'='Medium','High'='Highest'),
values=c('red','blue','green'))
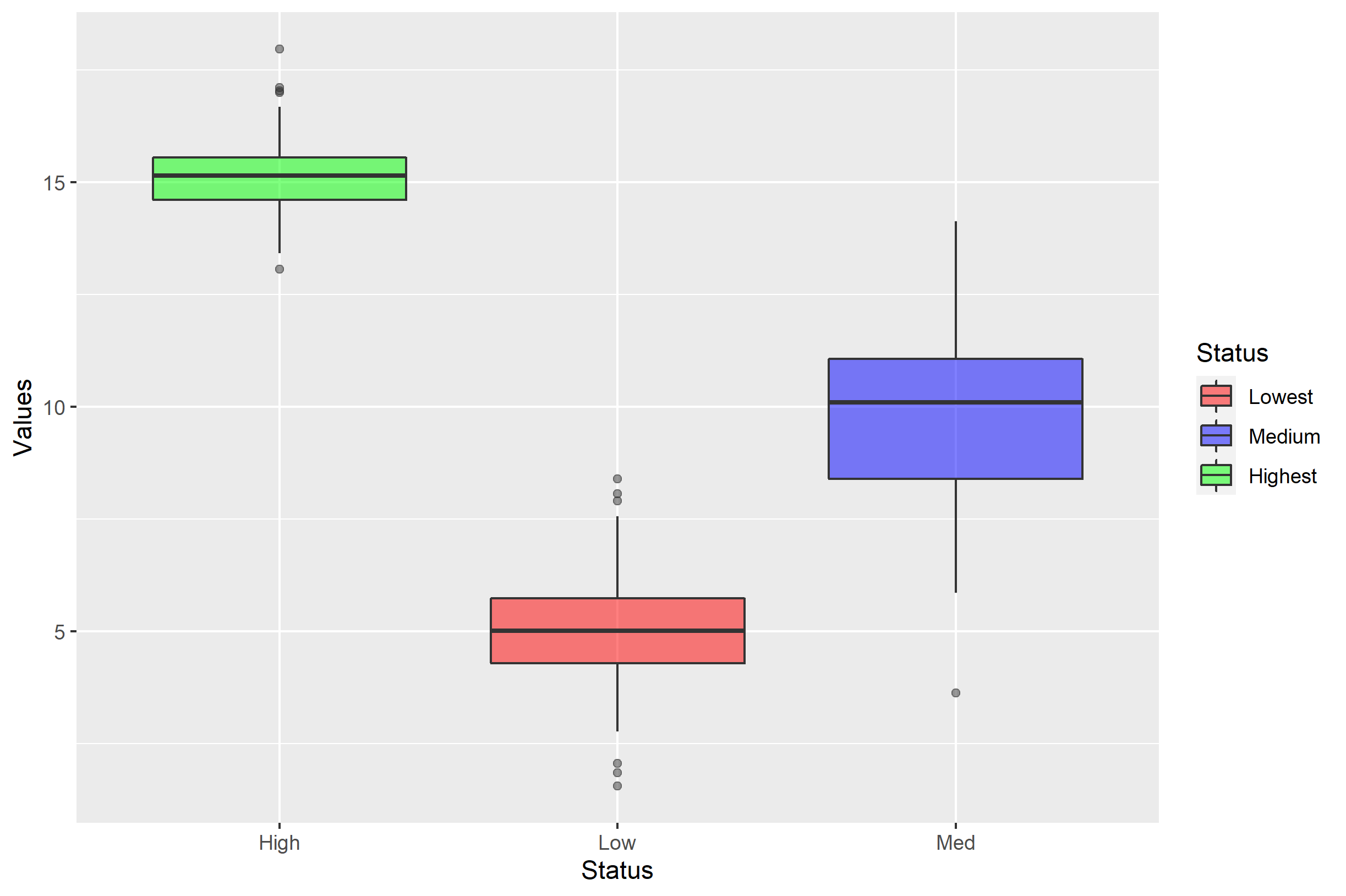
如果要更改图例中项的顺序,可以使用breaks=参数进行更改。在这里,我将向您展示所有合并的论点:
p + scale_fill_manual(
labels=c('Low'='Lowest','Med'='Medium','High'='Highest'),
values=c('red','blue','green'),
breaks=c('Low','Med','High'))
https://stackoverflow.com/questions/62866278
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号