
熊猫数据帧-迭代并与前值进行比较
熊猫数据帧-迭代并与前值进行比较
提问于 2020-07-21 17:17:28
import pandas as pd
data = {'Unique_ID': [44,66,12,76,57,83],
'Location 1': ['AA', 'BB','CC','DD','EE','FF'],
'Location 2': ['FF', 'CC','AA','EE','BB','CC'],
'Rank':[1,2,3,4,5,6]
}
pd.DataFrame (data)下面是示例数据集,如下所示
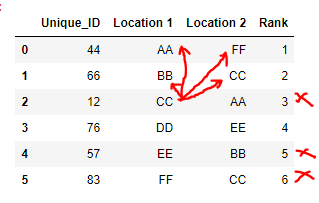
预期输出:
它是根据等级进行排序的。我正在寻找一个最终的数据rank (Df2)与一个最佳的‘位置1’和'location2‘组合基于排名。示例:
- Iteration-1:,因为这是最好的,所以没有什么可比较的,所以我们立即在新的dataframe (Df2)中插入第一条记录。
- Iteration-2:比较Location1和Location2,如果在lcoation1和location2的新的dataframe(d2)中存在这样的情况,那么在这个示例中不要插入insert,我们需要将第2级记录插入为"BB“和"CC”。
- Iteration-3:*检查新数据帧(D2)中是否存在"CC“或"AA”。如果一个或两个呈现,则不要将其更新为新的数据格式。在本例中,它们都退出了,因此不要将此记录更新为新的dataframe.
。
- Iteration-4:检查新数据中是否存在DD或EE。我们在新的dataframe中看不到它们,因此将此记录更新为新的dataframe
。
并遍历每一条记录.
提前谢谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-07-21 17:56:20
使用:
m1 = df[['Location 1', 'Location 2']].stack().duplicated()
m2 = ~m1.any(level=0)
df = df[m2]详细信息:
使用DataFrame.stack通过Location 1和Location 2到Multilevel系列重新定义数据,并使用Series.duplicated创建掩码m1。
print(m1)
0 Location 1 False
Location 2 False
1 Location 1 False
Location 2 False
2 Location 1 True
Location 2 True
3 Location 1 False
Location 2 False
4 Location 1 True
Location 2 True
5 Location 1 True
Location 2 True
dtype: bool在掩码Series.any上使用level=0上的m1并否定这一点,以创建一个新的布尔掩码m2。感谢@ScottBoston的建议。
print(m2)
0 True
1 True
2 False
3 True
4 False
5 False
dtype: bool最后,使用此掩码m2过滤数据文件中的行:
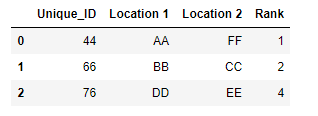
print(df)
Unique_ID Location 1 Location 2 Rank
0 44 AA FF 1
1 66 BB CC 2
3 76 DD EE 4页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63019702
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号