
为什么k-均值在科学学习中有预测作用,而DBSCAN/凝聚却没有?
Scikit-学习K-means的实现有一个predict()函数,可以应用于不可见的数据。其中,as DBSCAN和Agglomerative不具有predict()函数。
这三种算法都有fit_predict(),用于对模型进行拟合并进行预测。但是k-均值有predict(),它可以直接用于看不见的数据,而另一种算法则不然。
我非常清楚,有一些聚类算法,按照我的观点,predict()也不应该存在于K-means中。
这种差异背后的可能直觉/原因是什么?这仅仅是因为k均值执行"1NN分类“,所以它有一个predict()函数吗?
回答 1
Stack Overflow用户
发布于 2020-07-23 11:32:49
我的解释是,差异来自于计算集群的方式。在KMeans中,有一种向集群分配新点的本地方法,而不是在DBSCAN或聚集集群中。
( A) KMeans
在KMeans中,在簇的构造过程中,将一个数据点分配给具有最近质心的集群,然后更新质心。KMeans算法中的“预测”实际上是在不更新集群的情况下执行分配步骤。
如果假设新的数据点来自与“培训”集相同的分布,并且“培训”集具有足够的代表性,则可以合理地认为可以按照算法的启发分配新的数据点,而无需更新集群质心,从而进行预测。
当然,如果数据点分布可能发生变化,则应该在更新的数据集中重新运行KMeans集群。
( B) DBSCAN
DBSCAN通过查找数据集的高密度区域(由参数epsilon和min_points参数化)创建集群。这是通过计算点级属性来实现的(无论该点是核心点、直接可达点、可达点还是噪声点)。添加一个新的数据点可以修改相邻点的定义,从而使计算出的聚类过时。
举个例子,让我们看看这幅来自维基百科的插图,复制如下。在这个图像上有一个簇(red+yellow点)和一个噪声点(蓝色)。红点是核心点,黄色点是可达点。
{kind=link}
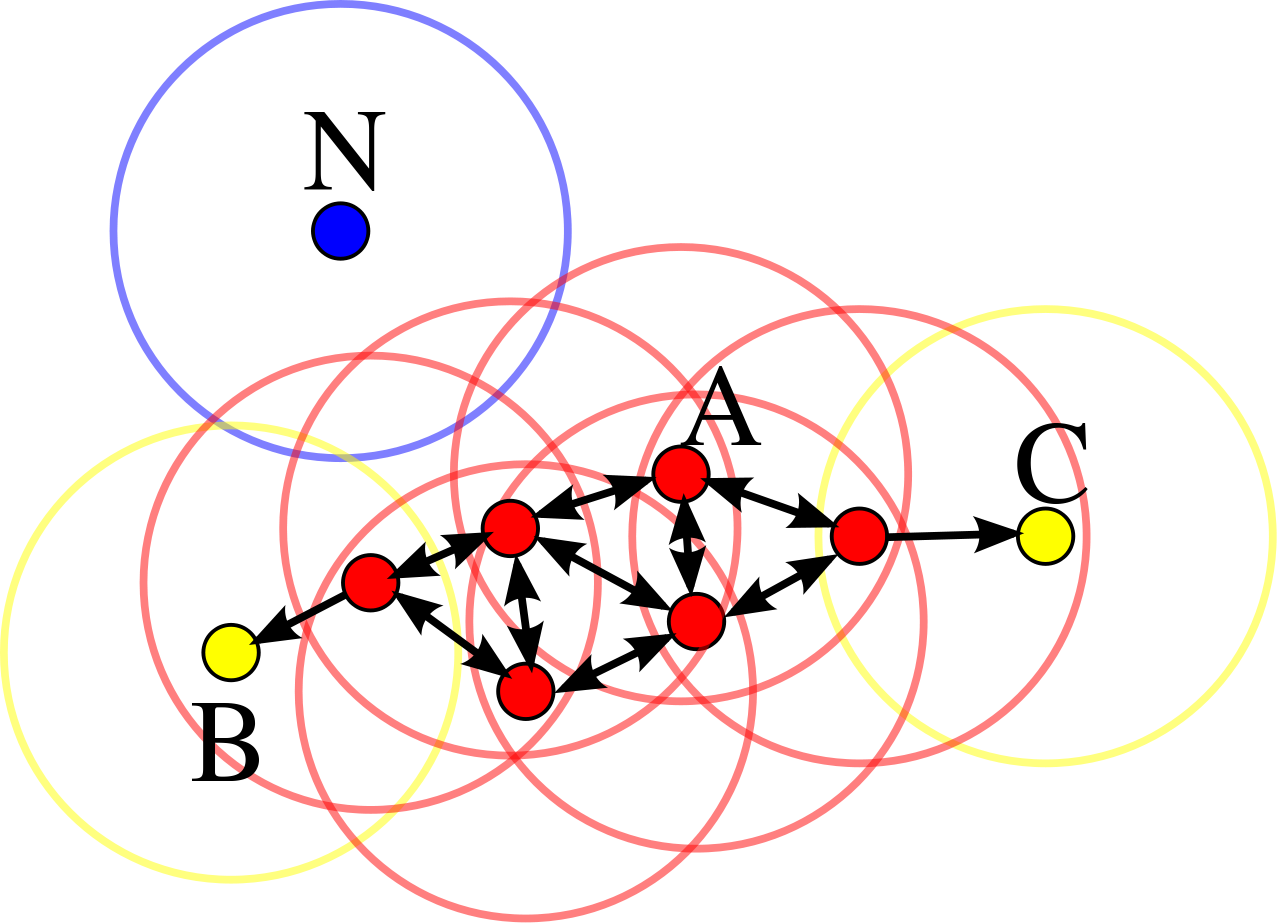
并考虑两种情况:
- 在A和N中间添加一个新的点将使N成为从A到A的一个可达点,因此属于该簇。
- 在N的epsilon邻域中添加(min_ point -1)新点,但在其他epsilon邻域(例如图片顶部)中添加新的点,将改变N的状态,它将成为一个核心点,并与新添加的点形成一个新的集群。
在这里,添加新的数据点显然需要重新计算集群。
( C)聚集聚类
聚类以迭代的方式从点开始构建聚类,并根据关联度量对它们进行合并。与DBSCAN类似,添加新的数据点可以完全修改最终的集群,因为它可以触发不同的合并。
例如,如果您在sklearn中选择的链接策略是“单”的,则如果两个集群的所有元素之间的最小距离低于选定的阈值,则合并群集。您可以很容易地发现,一个放置良好的新数据点可以触发两个集群之间的合并,否则这两个集群就会被分开。
因此,这里的预测还需要重新计算集群。
https://stackoverflow.com/questions/63037102
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号