
K均值聚类算法中如何寻找silhouette_score
K均值聚类算法中如何寻找silhouette_score
提问于 2020-07-30 08:45:18
我正在为K均值聚类算法寻找silhouette_score .实际上,我正在使用其他4种算法,我必须找到所有四种算法中的silhouette_score。我试图首先找到k均值集群,并为所有其他集群使用相同的代码。
import pandas as pd
import numpy as np
from sklearn.datasets import load_wine
df = load_wine()
from sklearn.preprocessing import MinMaxScaler
X_scaled_data = MinMaxScaler().fit_transform(df.data)
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=3).fit(X_scaled_data)
from sklearn.metrics import silhouette_score
silhouette_avg = silhouette_score(X_scaled_data, kmeans.labels_)
print("For n_clusters =", 3, "The average silhouette_score is :", silhouette_avg)以下是错误:
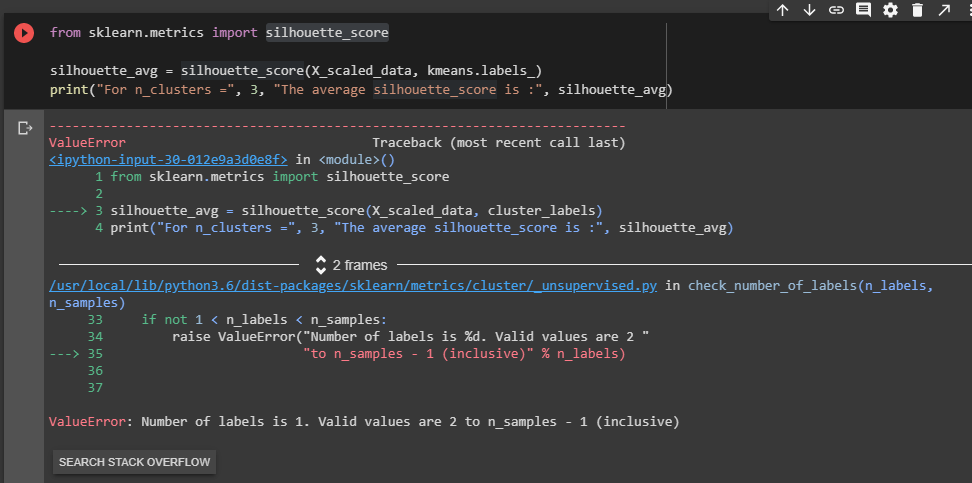
回答 1
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63169471
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号