
Lambda SQL Server RDS连接泄漏
问题
我在一个经常被调用的Lambda中使用mssql v6.2.0 (在标准负载下一致地~25个并发调用)。
我似乎在连接池或其他方面遇到了问题,因为我一直有大量打开的DB连接,这些连接淹没了我的数据库(SQL Server on RDS),导致Lambdas只需要超时等待查询结果。
我读过文档、各种类似的问题、Github问题等等,但是对于这个特定的问题,没有什么有效的。
我已经学到的东西
- I确实了解到跨调用池是可能的,这是因为在同一个容器中的调用之间共享了处理程序函数之外的变量。这让我觉得我应该只看到运行Lambda的每个容器的几个连接,但我不知道有多少连接,所以很难验证。最重要的是,池应该阻止我拥有大量的开放连接,所以有些东西不能正常工作。
- 有几种不同的使用
mssql的方法,我已经尝试过其中的几种。值得注意的是,我尝试用大小值指定了最大池大小,但得到了相同的结果。 - AWS建议您在尝试创建新池之前检查是否已经存在池。我试过了,但没有用。类似于
pool = pool || await createPool() - I知道,RDS代理的存在是为了帮助解决这种情况,但似乎(此时)没有为Server实例提供RDS代理。
- I确实有能力稍微减慢我的数据速度,但这对整个产品的性能有轻微的影响,所以我不想这样做只是为了避免解决DB连接问题。
- 没有检查,我一次看到了多达700个到DB的连接,这让我觉得存在某种漏洞,这可能不仅仅是高使用率的合理结果。
- 我没有找到一种方法来缩短Server端连接的TTL,这是re推荐的:发明幻灯片。也许这就是答案的一部分?

代码
'use strict';
/* Dependencies */
const sql = require('mssql');
const fs = require('fs').promises;
const path = require('path');
const AWS = require('aws-sdk');
const GeoJSON = require('geojson');
AWS.config.update({ region: 'us-east-1' });
var iotdata = new AWS.IotData({ endpoint: process.env['IotEndpoint'] });
/* Export */
exports.handler = async function (event) {
let myVal= event.Records[0].Sns.Message;
// Gather prerequisites in parallel
let [
query1,
query2,
pool
] = await Promise.all([
fs.readFile(path.join(__dirname, 'query1.sql'), 'utf8'),
fs.readFile(path.join(__dirname, 'query2.sql'), 'utf8'),
sql.connect(process.env['connectionString'])
]);
// Query DB for updated data
let results = await pool.request()
.input('MyCol', sql.TYPES.VarChar, myVal)
.query(query1);
// Prepare IoT Core message
let params = {
topic: `${process.env['MyTopic']}/${results.recordset[0].TopicName}`,
payload: convertToGeoJsonString(results.recordset),
qos: 0
};
// Publish results to MQTT topic
try {
await iotdata.publish(params).promise();
console.log(`Successfully published update for ${myVal}`);
//Query 2
await pool.request()
.input('MyCol1', sql.TYPES.Float, results.recordset[0]['Foo'])
.input('MyCol2', sql.TYPES.Float, results.recordset[0]['Bar'])
.input('MyCol3', sql.TYPES.VarChar, results.recordset[0]['Baz'])
.query(query2);
} catch (err) {
console.log(err);
}
};
/**
* Convert query results to GeoJSON for API response
* @param {Array|Object} data - The query results
*/
function convertToGeoJsonString(data) {
let result = GeoJSON.parse(data, { Point: ['Latitude', 'Longitude']});
return JSON.stringify(result);
}问题
请帮助我理解为什么我要失控的连接,以及如何修复它。额外积分:在Lambda上处理高DB并发性的理想策略是什么?
最终,这个服务需要处理当前负载的几倍--我意识到这将成为一个相当大的负载。我可以使用诸如read副本或其他提高读取性能的措施等选项,只要它们与Server兼容,而且它们不仅仅是编写正确的DB访问代码的警察。
如果我能改进这个问题,请告诉我。我知道有类似的,但我读过/尝试了很多,但没有找到他们的帮助。提前感谢!
相关材料
- https://forums.aws.amazon.com/thread.jspa?messageID=678029 (旧版,但similar)
- https://www.slideshare.net/AmazonWebServices/best-practices-for-using-aws-lambda-with-rdsrdbms-solutions-srv320 re:发明幻灯片deck
- https://www.jeremydaly.com/reuse-database-connections-aws-lambda/相关信息,但用于MySQL而不是Server
)
回答 2
Stack Overflow用户
发布于 2020-08-10 15:57:31
回答
经过4天的努力,我终于找到了答案。我所要做的就是扩大数据库。代码实际上和现在一样好。
我从db.t2.micro转到db.t3.small (或1 vCPU,1GB内存,2 vCPU和2GB内存),净成本约为15美元/莫。
理论
在我的例子中,DB可能无法同时处理所有调用的处理(这涉及几个地理计算)。我确实看到了CPU的上升,但我认为这是高开放连接的结果。当查询速度减慢时,并发调用就会堆积起来,因为Lambdas开始等待结果,最终导致它们超时,无法正确地关闭它们的连接。
比较:
Db.t2.微:
invocations
- 5000+
- 200+ DB连接(如果您继续运行)
- 50+并发
- ms Lambda持续时间,在空载
下~300 ms
Db.t3.小:
(constantly)
- ~5并发invocations
- ~33 ms Lambda持续时间<--快10倍!
CloudWatch指示板
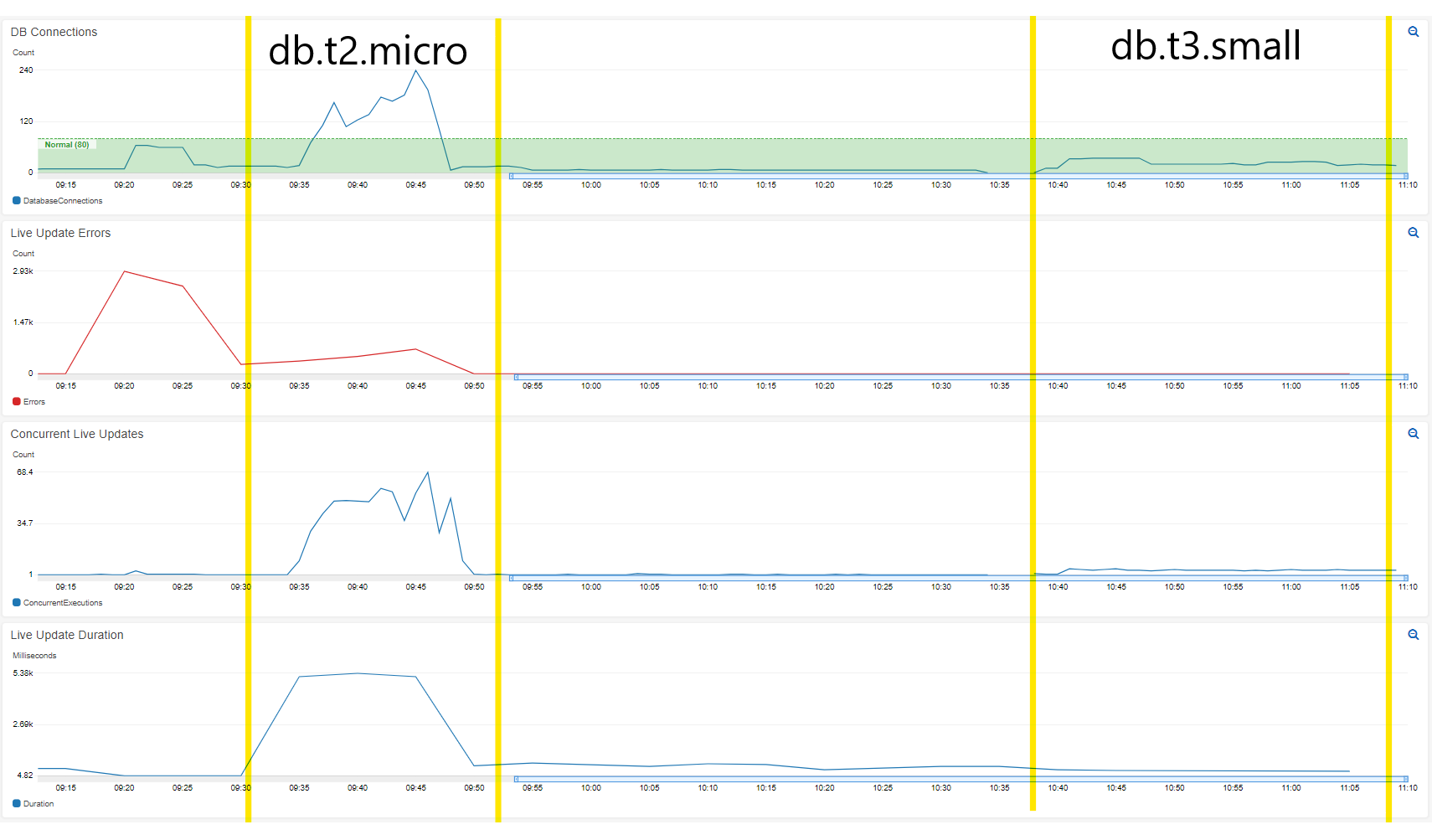
摘要
我觉得这个问题让我很困惑,因为它闻起来不像是容量问题。在过去,我几乎每次处理高DB连接时,都会出现代码错误。在那里尝试了各种选择之后,我认为这是“一些我需要理解的”“无服务器的神奇之处”。最后,它就像更改DB层一样简单。我的理解是,DB容量问题可以以除高CPU和内存使用率之外的其他方式表现出来,而且高连接可能是代码错误之外的结果。
最新情况(4个月内)
这继续取得很好的效果。令我印象深刻的是,双倍的DB资源似乎提供了> 2x的性能。现在,由于加载(或开发过程中的临时错误),db处理的数据库连接非常高(甚至超过1k)。我根本没有看到任何与数据库连接超时或数据库因加载而陷入困境的问题。从编写最初的时候起,我就添加了几个CPU密集型查询,以支持报告工作负载,并且它继续同时处理所有这些负载。
在编写本报告时,我们还将此设置部署到一个客户的生产中,并且处理该工作负载时没有出现任何问题。
Stack Overflow用户
发布于 2020-08-07 15:30:57
因此,连接池对Lambda没有好处,您可以做的是重用连接。
麻烦的是,每一个Lambda执行都会打开一个池,它会像你得到的那样淹没DB,你想要每个lambda容器有一个连接,你可以使用这样的db类(这很粗糙,但是如果你有问题的话,我知道)
export default class MySQL {
constructor() {
this.connection = null
}
async getConnection() {
if (this.connection === null || this.connection.state === 'disconnected') {
return this.createConnection()
}
return this.connection
}
async createConnection() {
this.connection = await mysql.createConnection({
host: process.env.dbHost,
user: process.env.dbUser,
password: process.env.dbPassword,
database: process.env.database,
})
return this.connection
}
async query(sql, params) {
await this.getConnection()
let err
let rows
[err, rows] = await to(this.connection.query(sql, params))
if (err) {
console.log(err)
return false
}
return rows
}
}
function to(promise) {
return promise.then((data) => {
return [null, data]
}).catch(err => [err])
}您需要理解的是,-- lambda执行是一个小虚拟机,它执行一个任务,然后停止,它确实在那里停留一段时间,如果其他人需要它,那么它与容器和连接一起被重用--单个任务----从没有多个连接到单个lambda。
希望这能让我知道你是否需要更多的细节!哦,欢迎来到堆栈溢出,这是一个很好的问题。
https://stackoverflow.com/questions/63302679
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号