
使用python从web中提取表数据
使用python从web中提取表数据
提问于 2020-08-17 11:38:06
我需要从一个类似于数千行的网站"https://geniusimpex.org/pakistan-import-data/“中提取一个表,所以我想使用bs4和selenium自动处理这个过程,但是当我提取该表时,只提取表头。这是我使用的代码
from bs4 import BeautifulSoup
from urllib.request import urlopen
url = "https://geniusimpex.org/pakistan-import-data/"
html = urlopen(url)
soup = BeautifulSoup(html, 'lxml')
type(soup)
soup.prettify()
print(soup.find_all('tr')) 它显示了以下输出
1:https://i.stack.imgur.com/GItzv.png
{kind=link}
如您所见,只提取第一行。请有人告诉我,为什么我不能提取这张桌子,我怎么能这样做呢?这会很有帮助的。对不起,如果我不清楚或无法解释我的问题。这是我第一次问关于堆栈溢出的问题。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-17 11:58:49
数据以Json的形式从外部URL加载。您可以使用此脚本加载以下信息:
import json
import requests
url = 'https://geniusimpex.org/wp-admin/admin-ajax.php?action=ge_forecast_list_data&order=asc&offset={offset}&limit=1000'
offset = 0
while True:
data = requests.get(url.format(offset=offset)).json()
# print data to screen:
for row in data.get('rows', []):
for k, v in row.items():
print('{:<30} {}'.format(k, v))
print('-' * 80)
if len(data.get('rows', [])) != 1000:
break
offset += 1000指纹:
...
--------------------------------------------------------------------------------
count T
importer_name <span file_id="27893" post_count="T" post_id="2157293">BISMILLAH STEEL FURNACE \n NEAR GRID STATION DEEWAN</span>
goods_description IRON AND STEEL REMELTABLE SCRAP HARMONIZED CODE: 7204.4990 REFERENCE NUMBER:UM/PAK/5146A ITN: X20200629019843 NWT WEIGHT-19.650 MT SHIPPERS LOAD, STOWAGE AND COUNT
hs_code
shipment_port NEWARK APT/NEW
gross_weight 19.65
number_of_packages 1
unit_of_packages PACKAGES
size_of_container 1 X 20FT
imported_from_name SEALINK INTERNATIONAL INC C/O\n UNIVERSAL METALS, ,
bill_of_lading_number SII145321
bill_of_lading_date <span data="10-08-2020">10-08-2020</span>
--------------------------------------------------------------------------------
count T
importer_name <span file_id="27938" post_count="T" post_id="2159597">ASAD SHAHZAD S/O FAQIR ZADA</span>
goods_description 1 USED VEHICLE TOYOTA VITZ CHASSIS NO: KSP130 -2204837
hs_code NA
shipment_port NAGOYA, AICHI
gross_weight .97
number_of_packages 1
unit_of_packages UNIT
size_of_container 1 X 40FT
imported_from_name KASHMIR MOTORS , 3055-9-104 KUZUTSUKA NIIGATA KITA
bill_of_lading_number TA200716H06- 10
bill_of_lading_date <span data="10-08-2020">10-08-2020</span>
--------------------------------------------------------------------------------
...编辑:要保存到CSV,可以使用以下脚本:
import json
import requests
import pandas as pd
url = 'https://geniusimpex.org/wp-admin/admin-ajax.php?action=ge_forecast_list_data&order=asc&offset={offset}&limit=1000'
offset = 0
all_data = []
while True:
data = requests.get(url.format(offset=offset)).json()
# print data to screen:
for row in data.get('rows', []):
all_data.append(row)
for k, v in row.items():
print('{:<30} {}'.format(k, v))
print('-' * 80)
if len(data.get('rows', [])) != 1000:
break
offset += 1000
df = pd.DataFrame(all_data)
df.to_csv('data.csv')生产:
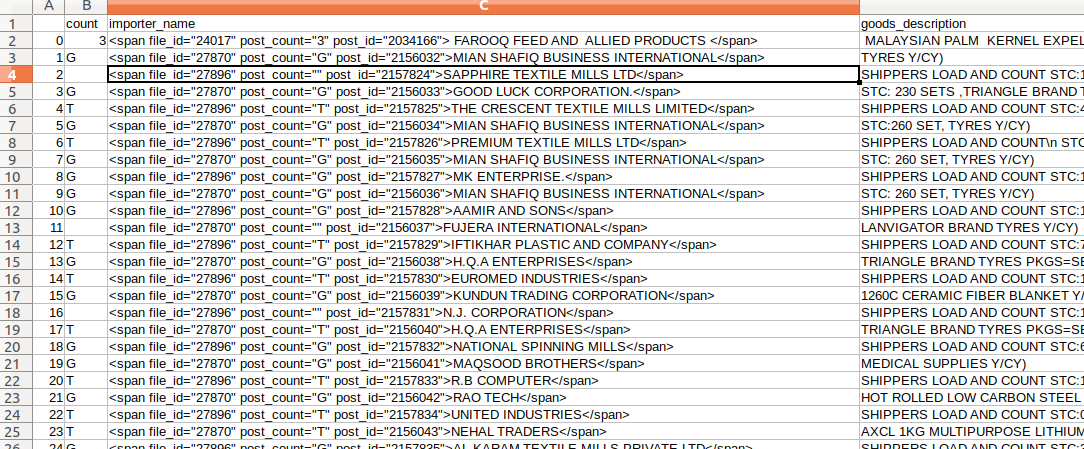
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63450045
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号