
为我的QLearning代理编写一个很好的奖励函数
我对ML还不熟悉,最近我学习了Q-Learning并手动编写了它(不使用Keras或TensorFlow之类的库),而我面临的问题是如何为我的代理编写一个好的奖励函数,我从编写以下简单的奖励函数开始:
当从X,Y移动到X1时,Y1:返回(距离(从X,Y到目标)-距离(从X1,Y1到目标))
这意味着,每当它向目标移动时,它就得到了积极的回报,而且它在一个空的2D平原上运行得很好。
但是当我增加障碍的时候,这个函数没有帮助,代理人选择了最短的路径,直到目标永远被困在障碍物中,我增加了对原地的惩罚,它再次被堵在墙上,但是这一次来回来回,因为惩罚+奖励的总和是0,它已经得到了一个积极的奖励,所以这是一个有利的途径。然后我增加了两次通过同一个正方形的惩罚,但是我仍然觉得这可能变得太复杂了,而且必须有一个更简单的方法来做到这一点。
起始位置(格林是代理人,红色是目标)

被困在阻塞的最短直路上
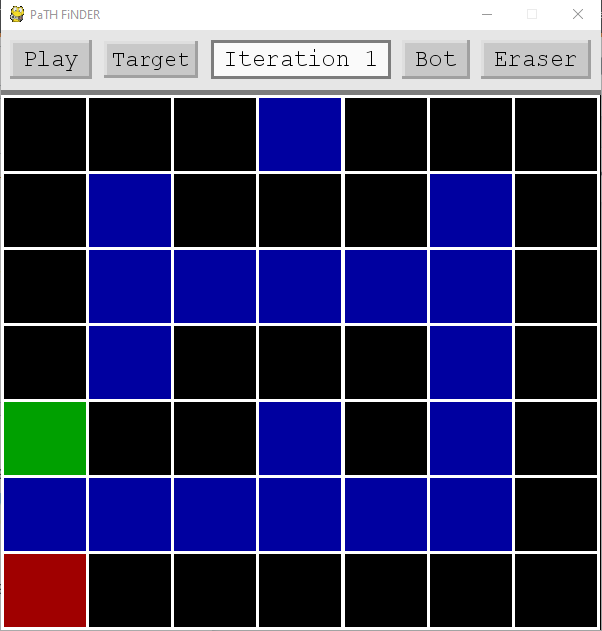
我意识到,在阅读了一些关于奖励的文章后,我已经理解/做了很多错误的事情,从让我的奖励一步一步上升到2k,而不是在1,1,以及没有明确的区分何时使用消极的和积极的奖励。
我的状态vs动作的内存数组由n个n=rows*columns状态和5个操作(上、右、下、左、内)组成。
因此,知道我的代理应该找到到达目标的最短可用路径(而不是阻止),那么奖励函数应该是什么样的呢?为什么?按照我学到的算法,他们并没有真正指定Epsilon、Gamma和LearningRate的值,因此我将它们分别设置为0.2、0.85和0.75。
如果您想在代码中发送奖励函数,我的代码在python中。
PS:我搜索了StackOverflow上和下的问题,我发现的只是参考和文章,所有这些都解释了奖励函数应该做什么,但没有详细说明如何做到这一点,或者将我的查询变成奖励函数。
以下是我在Github上的代码文件(No ):https://github.com/EjHam98/LearningMachineLearning/blob/master/QLearning.py
回答 1
Stack Overflow用户
发布于 2020-08-17 10:19:20
如果您的环境状态-动作空间是非常大的。仅考虑10个障碍,总状态将大于49x48x47c10,这比10e13多,这里甚至不考虑行动和其他可能的障碍数。
因此,最好使用功率全Deep Q-learning函数逼近器。
- 观察-表示迷宫(或图像)的2d网格
- 代理当前观察的状态堆栈以及以前的一些帧(2,3)。
- 报酬结构
- -1 for each time step
- +ve reward for reaching target state
- -ve reward for hitting obstacleshttps://stackoverflow.com/questions/63445906
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号