
如何根据python中的频率和值为每个用户标识创建字云图
如何根据python中的频率和值为每个用户标识创建字云图
提问于 2020-08-31 17:40:06
我试图为每个用户创建基于单词和计数频率的每个单词云图,我想将word云图像路径的输出与UID.Do一起存储,我需要应用组吗?任何帮助都将不胜感激。
|UID |word |count
=================================================
|ccf878ec9315|RT |28
|ccf878ec9315|Newpin |6
|ccf878ec9315|Benefit Bond |6
|ccf878ec9315|Covid |5
|ccf878ec9315|Blues |5
|ccf878ec9316|TPG |10
|ccf878ec9316|Learn |8
|ccf878ec9316|An |6
|ccf878ec9317|GIINs Market Roadmap |9
|ccf878ec9317|amp |5
|ccf878ec9317|Varsity |3
|ccf878ec9318|International Womens Day |10
|ccf878ec9318|Solving |8
|ccf878ec9318|Hadewych |4
|ccf878ec9319|GIF16 |4
|ccf878ec9319|Kuyper |9
|ccf878ec9320|Impact Investments |8
|ccf878ec9320|Climate |3 我尝试使用频率计数,它拥有整个数据集的所有数据。但是我无法为每个UID创建单词云图。
from wordcloud import WordCloud
wc = WordCloud(width=800, height=400, max_words=200).generate_from_frequencies(data)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show() 回答 1
Stack Overflow用户
回答已采纳
发布于 2020-08-31 17:58:18
data in generate_from_frequencies(data)需要是类似于{'RT': 28, 'Newpin': 6, 'Benefit Bond': 6, 'Covid': 5, ...}的Python字典。下面是从给定的dataframe创建这样一个字典的方法:
import pandas as pd
import numpy as np
df = pd.DataFrame({'UID': ['ccf878ec9315', 'ccf878ec9315', 'ccf878ec9315', 'ccf878ec9315', 'ccf878ec9315',
'ccf878ec9316', 'ccf878ec9316', 'ccf878ec9316', 'ccf878ec9317', 'ccf878ec9317',
'ccf878ec9317', 'ccf878ec9318', 'ccf878ec9318', 'ccf878ec9318', 'ccf878ec9319',
'ccf878ec9319', 'ccf878ec9320', 'ccf878ec9320'],
'word': ['RT', 'Newpin', 'Benefit Bond', 'Covid', 'Blues', 'TPG', 'Learn', 'An',
'GIINs Market Roadmap', 'amp', 'Varsity', 'International Womens Day', 'Solving', 'Hadewych',
'GIF16', 'Kuyper', 'Impact Investments', 'Climate'],
'count': [28, 6, 6, 5, 5, 10, 8, 6, 9, 5, 3, 10, 8, 4, 4, 9, 8, 3]})
data = {wrd: cnt for wrd, cnt in zip(df['word'], df['count'])}
from wordcloud import WordCloud
wc = WordCloud(width=800, height=400, max_words=200).generate_from_frequencies(data)
import matplotlib.pyplot as plt
plt.figure(figsize=(10, 10))
plt.imshow(wc, interpolation='bilinear')
plt.axis('off')
plt.show()
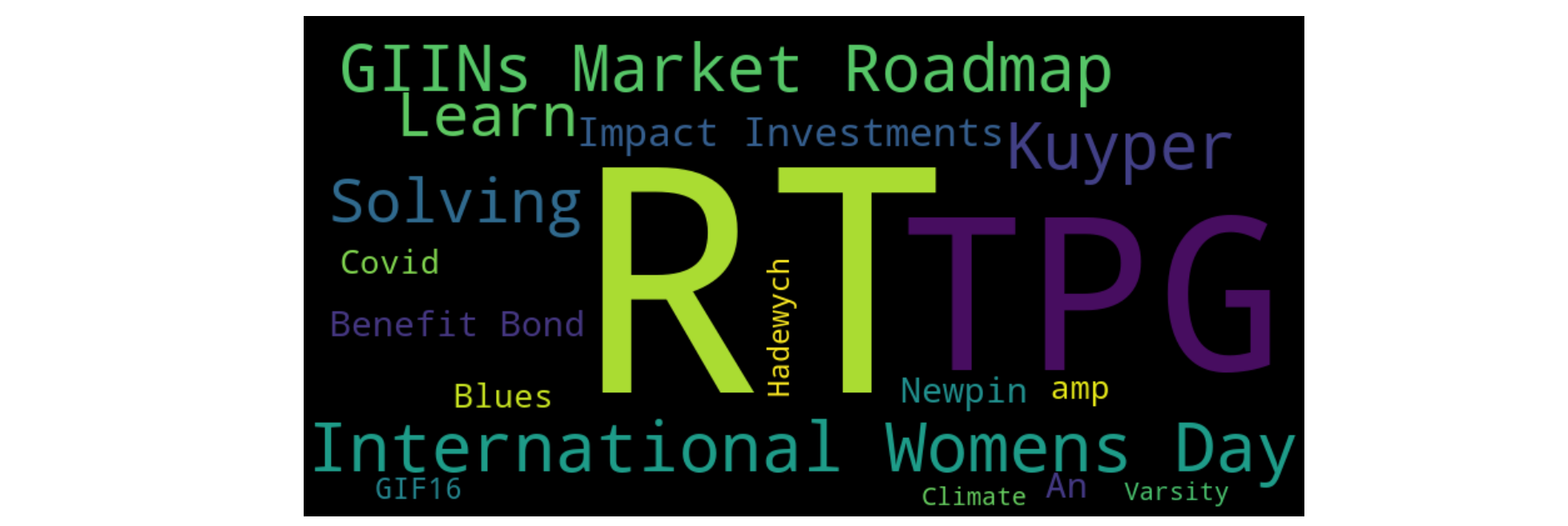
另一种方法是在熊猫体内完全创建词典:
data = df.set_index('word')['count'].to_dict()若要创建每个UID的wordcloud,请执行以下操作:
uids = np.unique(df['UID'])
fig, axes = plt.subplots(nrows=(len(uids)+2)//3, ncols=3, figsize=(20, 8),
gridspec_kw={'hspace': 0.05, 'wspace': 0.05, 'left': 0.01, 'right': 0.99, 'top': 0.99, 'bottom': 0.01})for uid, ax in zip(uids, axes.ravel()):
data = df[df['UID'] == uid].set_index('word')['count'].to_dict()
wc = WordCloud(width=800, height=400, max_words=200).generate_from_frequencies(data)
ax.imshow(wc, interpolation='bilinear')
ax.set_title(f'UID = {uid}')
ax.axis('off')
plt.show()

页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63675620
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号