
OneHotEncoding蛋白序列
OneHotEncoding蛋白序列
提问于 2020-09-03 13:31:22
我有下面列出的序列的原始数据,并且尝试使用一种热编码,然后将它们存储在一个新的dataframe中,我试图用下面的代码来完成它,但是无法存储,因为之后我得到了以下输出:
代码:
onehot_encoder = OneHotEncoder()
sequence = np.array(list(x_train['sequence'])).reshape(-1, 1)
encoded_sequence = onehot_encoder.fit_transform(sequence).toarray()
encoded_sequence
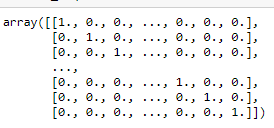
但要犯错误
ValueError: Wrong number of items passed 12755, placement implies 1回答 1
Stack Overflow用户
回答已采纳
发布于 2020-09-03 16:12:58
您得到了这个奇怪的数组,因为它将每个序列作为一个条目来处理,并尝试对其进行一个热编码,因此我们可以使用一个示例:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder
df = pd.DataFrame({'sequence':['AQAVPW','AMAVLT','LDTGIN']})
enc = OneHotEncoder()
seq = np.array(df['sequence']).reshape(-1,1)
encoded = enc.fit(seq)
encoded.transform(seq).toarray()
array([[0., 1., 0.],
[1., 0., 0.],
[0., 0., 1.]])
encoded.categories_
[array(['AMAVLT', 'AQAVPW', 'LDTGIN'], dtype=object)]因为你的条目是唯一的,所以你得到了所有的零矩阵。如果使用pd.get_dummies,您可以更好地理解这一点。
pd.get_dummies(df['sequence'])
AMAVLT AQAVPW LDTGIN
0 0 1 0
1 1 0 0
2 0 0 1有两种方法可以做到这一点,一种方法是简单地计算氨基酸的发生,并将其作为一个预测指标,我希望我的氨基酸是正确的(从很久以前的学校):
from Bio import SeqIO
from Bio.SeqUtils.ProtParam import ProteinAnalysis
pd.DataFrame([ProteinAnalysis(i).count_amino_acids() for i in df['sequence']])
A C D E F G H I K L M N P Q R S T V W Y
0 2 0 0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 1 1 0
1 2 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 0 0
2 0 0 1 0 0 1 0 1 0 1 0 1 0 0 0 0 1 0 0 0另一种方法是拆分序列,并按位置进行编码,这要求序列长度相同,并且您有足够的内存:
byposition = df['sequence'].apply(lambda x:pd.Series(list(x)))
byposition
0 1 2 3 4 5
0 A Q A V P W
1 A M A V L T
2 L D T G I N
pd.get_dummies(byposition)
0_A 0_L 1_D 1_M 1_Q 2_A 2_T 3_G 3_V 4_I 4_L 4_P 5_N 5_T 5_W
0 1 0 0 0 1 1 0 0 1 0 0 1 0 0 1
1 1 0 0 1 0 1 0 0 1 0 1 0 0 1 0
2 0 1 1 0 0 0 1 1 0 1 0 0 1 0 0页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63724745
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号