
用Python中的df.shift循环列
假设您有一个这样的数据文件:
df = pd.DataFrame({'A': [3, 1, 2, 3],
'B': [5, 6, 7, 8]})
df
A B
0 3 5
1 1 6
2 2 7
3 3 8现在我想对每一列进行倾斜和计算。我将这些值按我希望它们在索引中倾斜的方式放置:
range_span = range(4)
result = pd.DataFrame(index=range_span)然后,我试着用以下方法来检查结果:
for c in df.columns:
for i in range_span:
result.iloc[i][c] = df[c].shift(i).max()
result这只返回索引。我预料到了这样的事情:
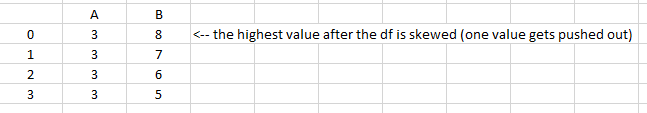
回答 1
Stack Overflow用户
发布于 2020-09-06 01:01:15
你有三个关键问题:
问题1
在这条线
result.iloc[i][c] = df[c].shift(i).max()引发警告,以帮助理解为什么result为空。
...\pandas\core\indexing.py:670: SettingWithCopyWarning:
一个值试图在来自一个的片的一个DataFrame副本上设置。
请参阅文档中的注意事项:https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy
根据他们的文件:
dfmi['one']['second'] = value
# becomes
dfmi.__getitem__('one').__setitem__('second', value)由于iloc[i]将返回该行的slice (也称为副本),所以您无法设置原始的dataframe result。此外,这也是为什么iloc在获得str索引时没有提出问题的原因。在第二节中解释了。
相反,您可以使用iloc (可能与str一起使用loc ),如下所示:
>>> df
A B C
0 1 10 100
1 2 20 200
2 3 30 300
>>> df.iloc[1, 2]
200
>>>df.iloc[[1, 2], [1, 2]]
B C
1 20 200
2 30 300
>>> df.iloc[1:3, 1:3]
B C
1 20 200
2 30 300
>>> df.iloc[:, 1:3]
B C
0 10 100
1 20 200
2 30 300
# ..and so on问题2
如果您修复了问题#1,那么您将看到以下错误:
result.iloc[[i][c]] = df[c].shift(i).max()
TypeError: list indices must be integers or slices, not str也来自他们的文件:
integer-location property DataFrame.iloc:纯基于
的索引,用于按位置进行选择。
在for c in df.columns:,您传递的是列名A,B,它是str,而不是int。对loc列索引使用str。
这并没有因为问题#1而引发TypeError,因为c被作为__setitem__()的参数传递。
问题3
通常,如果没有像dataframe这样的特殊功能,就不能扩展combine。
# using same df from #1
>>> df.iloc[1, 3] = 300
Traceback (most recent call last):
File "~\pandas\core\indexing.py", line 1394, in _has_valid_setitem_indexer
raise IndexError("iloc cannot enlarge its target object")
IndexError: iloc cannot enlarge its target object更容易的修复方法是在操作完成后使用dict并转换为DataFrame。或者直接创建DataFrame以匹配或拥有更大的大小:
>>> df2 = pd.DataFrame(index=range(4), columns=range(3))
>>> df2
0 1 2
0 NaN NaN NaN
1 NaN NaN NaN
2 NaN NaN NaN
3 NaN NaN NaN将所有问题结合起来,正确的解决办法是:
import pandas as pd
df = pd.DataFrame({'A': [3, 1, 2, 3],
'B': [5, 6, 7, 8]})
result = pd.DataFrame(index=df.index, columns=df.columns)
for col in df.columns:
for index in df.index:
result.loc[index, col] = df[col].shift(index).max()
print(result)输出:
A B
0 3 8
1 3 7
2 3 6
3 3 5https://stackoverflow.com/questions/63720813
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号