
日期连续性
日期连续性
提问于 2020-09-18 21:05:36
我有调查数据,雇员必须输入他的数据,以便不断地回答以下问题。我试着用R来检查他们是否连续地填写数据。
数据如下:
EmployeeID <- c(101,101,101,102,102,102,102,104,104)
Created <- c(2020-06-19,2020-06-20,2020-06-21,2020-06-24,2020-06-25,2020-06-28,2020-06-28,2020-06-23,2020-06-24)
Updated <- c(2020-06-19,2020-06-20,2020-06-21,2020-06-24,2020-06-25,2020-06-28,2020-06-28,2020-06-23,2020-06-24)
happy <- c("True", "false", "false"," ", "false", "True","false", "True", "false")
active <- c("false", "false", " "," ", "false", "True"," ", "false", "false")
sad <- c("True", "false", "false"," ", "false", "True","false", "True", "false")
energitic <- c("True", "false", "false"," ", "false", "True","false", "True", "false")
df <- data.frame(EmployeeID, Created, Updated, happy, active, sad, energitic)预期产出:
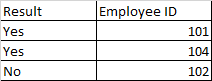
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-09-18 21:16:56
使用dplyr的一种方法
library(dplyr)
df %>%
group_by(EmployeeID) %>%
summarize(
continuous = all(do.call(seq, c(as.list(range(Created)), by = "day")) %in% Created),
.groups = "drop"
)
# # A tibble: 3 x 2
# EmployeeID continuous
# <dbl> <lgl>
# 1 101 TRUE
# 2 102 FALSE
# 3 104 TRUE 顺便说一句,你的样本数据并不代表你的建议。2020-06-19不是日期,而是计算为1995的表达式。我更新了上面的答案,以说明它们是真实的Date对象。
以下是更新的数据:
df <- local({
EmployeeID <- c(101, 101, 101, 102, 102, 102, 102, 104, 104)
Created <- c("2020-06-19", "2020-06-20", "2020-06-21", "2020-06-24", "2020-06-25", "2020-06-28", "2020-06-28", "2020-06-23", "2020-06-24")
Updated <- c("2020-06-19", "2020-06-20", "2020-06-21", "2020-06-24", "2020-06-25", "2020-06-28", "2020-06-28", "2020-06-23", "2020-06-24")
happy <- c("True", "false", "false"," ", "false", "True","false", "True", "false")
active <- c("false", "false", " "," ", "false", "True"," ", "false", "false")
sad <- c("True", "false", "false"," ", "false", "True","false", "True", "false")
energitic <- c("True", "false", "false"," ", "false", "True","false", "True", "false")
data.frame(EmployeeID, Created, Updated, happy, active, sad, energitic)
})
df[,c("Created","Updated")] <- lapply(df[,c("Created","Updated")], as.Date)Stack Overflow用户
发布于 2020-09-19 06:09:21
您可以通过获取连续的Created日期值的差异来检查其连续性,并查看它们的all值是否有1的差异。
这可以用dplyr来完成:
library(dplyr)
df %>%
group_by(EmployeeID) %>%
summarise(Result = all(diff(Created) == 1))
# EmployeeID Result
# <dbl> <lgl>
#1 101 TRUE
#2 102 FALSE
#3 104 TRUE R基地:
aggregate(Created~EmployeeID, df, function(x) all(diff(x) == 1))和data.table:
library(data.table)
setDT(df)[, .(Result = all(diff(Created) == 1)), EmployeeID]页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/63962813
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号