
Solr Cloud中碎片/副本数量的最佳实践
我运行的SolrCloud有3个solr和3个动物园管理员实例。对于容错,我现在每个solr节点有3个碎片和3个副本。
所以:
numShards [3]
maxShardsPernode[3]
autoAddReplicas [false]
replicationFactor [3]
nrtReplicas[3]推荐这样做吗?如果我已经有了3个碎片,为什么我也需要3个这个碎片的副本呢?
回答 1
Stack Overflow用户
发布于 2020-09-20 07:38:04
切分对于以下方面非常重要:
performance/throughput.
- 它允许您水平拆分或缩放内容卷,
- 允许您跨碎片(可能在多个节点上)分发操作,例如索引跟踪操作,从而增加了
- 。
复制:复制的目的既是为了确保高可用性,也是为了提高搜索查询性能,尽管其主要目的往往是为了更好地容错。这是通过不将副本碎片存储在与其主碎片相同的节点上来实现的。
复制的优点:
可以创建用于搜索查询的operations
- Load、、
- 、读写负载和分发版,为从实例创建
- 高可用性,以扩展查询性能
建议将复制因子设置为至少3,这样即使在机架上发生了一些事情,一个副本也始终是安全的。
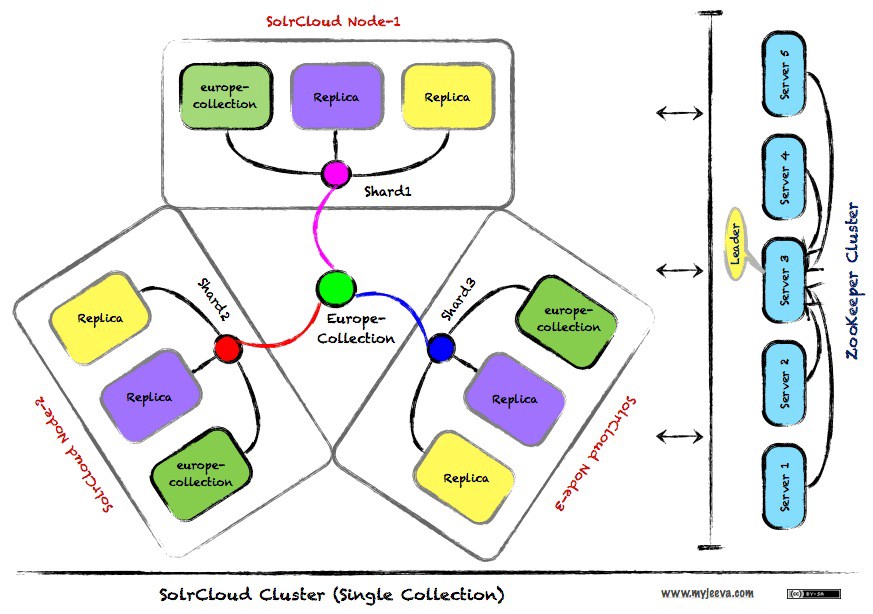
假设您有3个solr服务器实例,名为server1、server2和server3。您已经为您的收藏创建了3个碎片。每个服务器上都有一个碎片,分别是Shard1 on server1,shard2 on server 2和shard3 on server3。
让我们在每个服务器上拥有每个碎片的3个副本。
因此,您的server1将有shard1,其他碎片的副本,如碎片2和碎片3。其他服务器也是如此。
如果2台服务器发生故障,那么您就有一台服务器,其中包含了您所收集的所有数据。
这就是复制在实现高可用性方面的美妙之处。
https://stackoverflow.com/questions/63961255
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号