
海王星-如何获得所有节点的比例权重gremlin距离
在下面的场景中,我很难用gremlin查询。这是有向图(可能是循环的)。
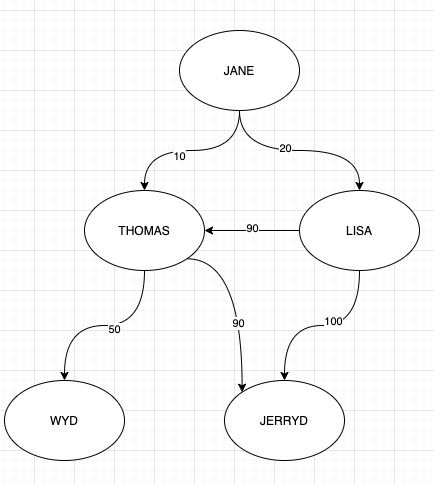
我希望从节点"Jane“开始,得到最上面的N个有利节点,其中,偏好定义为:
favor(Jane->Lisa) = edge(Jane,Lisa) / total weight from outwards edges of Lisa
favor(Jane->Thomas) = favor(Jane->Thomas) + favor(Jane->Lisa) * favor(Lisa->Thomas)
favor(Jane->Jerryd) = favor(Jane->Thomas) * favor(Thomas->Jerryd) + favor(Jane->Lisa) * favor(Lisa->Jerryd)
favor(Jane->Jerryd) = [favor(Jane->Thomas) + favor(Jane->Lisa) * favor(Lisa->Thomas)] * favor(Thomas->Jerryd) + favor(Jane->Lisa) * favor(Lisa->Jerryd)
and so .. on我的意思是用手工计算得到的图,
这对于编程来说很简单,但我不知道用gremlin甚至sparql查询它有多有趣。
下面是创建此示例图的查询:
g
.addV('person').as('1').property(single, 'name', 'jane')
.addV('person').as('2').property(single, 'name', 'thomas')
.addV('person').as('3').property(single, 'name', 'lisa')
.addV('person').as('4').property(single, 'name', 'wyd')
.addV('person').as('5').property(single, 'name', 'jerryd')
.addE('favor').from('1').to('2').property('weight', 10)
.addE('favor').from('1').to('3').property('weight', 20)
.addE('favor').from('3').to('2').property('weight', 90)
.addE('favor').from('2').to('4').property('weight', 50)
.addE('favor').from('2').to('5').property('weight', 90)
.addE('favor').from('3').to('5').property('weight', 100)我要找的只是:
[Lisa, computedFavor]
[Thomas, computedFavor]
[Jerryd, computedFavor]
[Wyd, computedFavor]我在努力不配合循环图来调整重量。这就是我到目前为止能够查询的地方:https://gremlify.com/f2r0zy03oxc/2
g.V().has('name','jane'). // our starting node
repeat(
union(
outE() // get only outwards edges
).
otherV().simplePath()). // produce simple path
emit().
times(10). // max depth of 10
path(). // attain path
by(valueMap())处理stephen的评论:
favor(Jane->Jerryd) =
favor(Jane->Thomas) * favor(Thomas->Jerryd)
+ favor(Jane->Lisa) * favor(Lisa->Jerryd)
// note we can expand on favor(Jane->Thomas) in above expression
//
// favor(Jane->Thomas) is favor(Jane->Thomas)@directEdge +
// favor(Jane->Lisa) * favor(Lisa->Thomas)
//计算实例
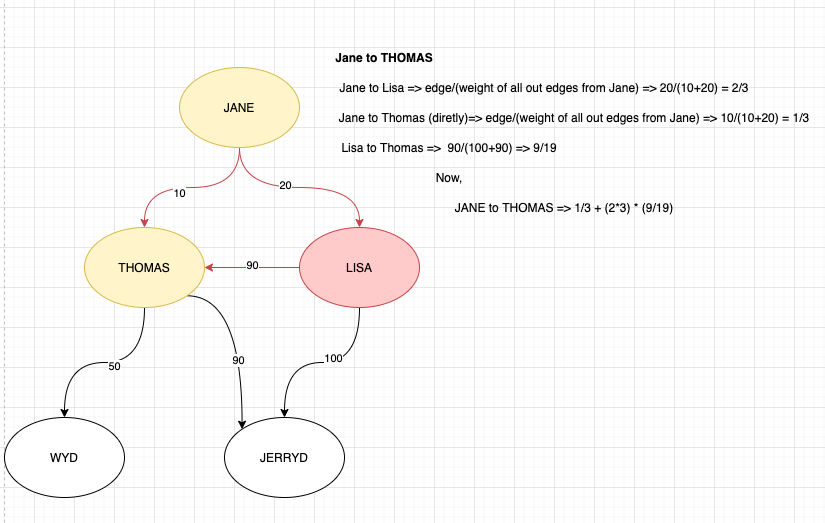
Jane to Lisa => 20/(10+20) => 2/3
Lisa to Jerryd => 100/(100+90) => 10/19
Jane to Lisa to Jerryd => 2/3*(10/19)
Jane to Thomas (directly) => 10/(10+20) => 1/3
Jane to Lisa to Thomas => 2/3 * 90/(100+90) => 2/3 * 9/19
Jane to Thomas => 1/3 + (2/3 * 9/19)
Thomas to Jerryd => 90/(90+50) => 9/14
Jane to Thomas to Jerryd => [1/3 + (2/3 * 9/19)] * (9/14)
Jane to Jerryd:
= Jane to Lisa to Jerryd + Jane to Thomas to Jerryd
= 2/3 * (10/19) + [1/3 + (2/3 * 9/19)] * (9/14)这里有一些psedocode:
def get_favors(graph, label="jane", starting_favor=1):
start = graph.findNode(label)
queue = [(start, starting_favor)]
favors = {}
seen = set()
while queue:
node, curr_favor = queue.popleft()
# get total weight (out edges) from this node
total_favor = 0
for (edgeW, outNode) in node.out_edges:
total_favor = total_favor + edgeW
for (edgeW, outNode) in node.out_edges:
# if there are no favors for this node
# take current favor and provide proportional favor
if outNode not in favors:
favors[outNode] = curr_favor * (edgeW / total_favor)
# it already has some favor, so we add to it
# we add proportional favor
else:
favors[outNode] += curr_favor * (edgeW / total_favor)
# if we have seen this edge, and node ignore
# otherwise, transverse
if (edgeW, outNode) not in seen:
seen.add((edgeW, outNode))
queue.append((outNode, favors[outNode]))
# sort favor by value and return top X
return favors回答 2
Stack Overflow用户
发布于 2020-09-24 18:34:28
这里有一个Gremlin查询,我相信它正确地应用了您的公式。我将首先粘贴完整的最终查询,然后就所涉及的步骤说几句话。
gremlin> g.withSack(1).V().
......1> has('name','jane').
......2> repeat(outE().
......3> sack(mult).
......4> by(project('w','f').
......5> by('weight').
......6> by(outV().outE().values('weight').sum()).
......7> math('w / f')).
......8> inV().
......9> simplePath()).
.....10> until(has('name','jerryd')).
.....11> sack().
.....12> sum()
==>0.768170426065163 查询从Jane开始,一直遍历到曾傑瑞D的所有路径都被检查过。在此过程中,为每个遍历器维护一个sack,其中包含每个关系的计算权重值乘以一起。第6行的计算发现所有可能来自前一个顶点的边权值,第7行的math步骤用于将当前边上的权重除以该和。最后,在第12行将每个计算结果相加在一起。如果删除最后的sum步骤,您可以看到中间结果。
gremlin> g.withSack(1).V().
......1> has('name','jane').
......2> repeat(outE().
......3> sack(mult).
......4> by(project('w','f').
......5> by('weight').
......6> by(outV().outE().values('weight').sum()).
......7> math('w / f')).
......8> inV().
......9> simplePath()).
.....10> until(has('name','jerryd')).
.....11> sack()
==>0.2142857142857143
==>0.3508771929824561
==>0.2030075187969925 要查看所执行的路由,可以将path步骤添加到查询中。
gremlin> g.withSack(1).V().
......1> has('name','jane').
......2> repeat(outE().
......3> sack(mult).
......4> by(project('w','f').
......5> by('weight').
......6> by(outV().outE().values('weight').sum()).
......7> math('w / f')).
......8> inV().
......9> simplePath()).
.....10> until(has('name','jerryd')).
.....11> local(
.....12> union(
.....13> path().
.....14> by('name').
.....15> by('weight'),
.....16> sack()).fold())
==>[[jane,10,thomas,90,jerryd],0.2142857142857143]
==>[[jane,20,lisa,100,jerryd],0.3508771929824561]
==>[[jane,20,lisa,90,thomas,90,jerryd],0.2030075187969925] 这种方法还考虑到添加任何直接连接,根据您的公式,我们可以看到,如果我们使用Thomas作为目标。
gremlin> g.withSack(1).V().
......1> has('name','jane').
......2> repeat(outE().
......3> sack(mult).
......4> by(project('w','f').
......5> by('weight').
......6> by(outV().outE().values('weight').sum()).
......7> math('w / f')).
......8> inV().
......9> simplePath()).
.....10> until(has('name','thomas')).
.....11> local(
.....12> union(
.....13> path().
.....14> by('name').
.....15> by('weight'),
.....16> sack()).fold())
==>[[jane,10,thomas],0.3333333333333333]
==>[[jane,20,lisa,90,thomas],0.3157894736842105] 这些额外的步骤是不需要的,但是在调试像这样的查询时,包含path是很有用的。而且,这不是必要的,但也许只是为了一般的兴趣,我要补充的是,您也可以从这里得到最后的答案,但是我包含的第一个查询是您真正需要的。
g.withSack(1).V().
has('name','jane').
repeat(outE().
sack(mult).
by(project('w','f').
by('weight').
by(outV().outE().values('weight').sum()).
math('w / f')).
inV().
simplePath()).
until(has('name','thomas')).
local(
union(
path().
by('name').
by('weight'),
sack()).fold().tail(local)).
sum()
==>0.6491228070175439 如果这些都不清楚,或者我误解了公式,请告诉我。
编辑以添加
为了找到所有可以从Jane获得的结果,我必须稍微修改一下查询。最后的unfold只是为了使结果更容易阅读。
gremlin> g.withSack(1).V().
......1> has('name','jane').
......2> repeat(outE().
......3> sack(mult).
......4> by(project('w','f').
......5> by('weight').
......6> by(outV().outE().values('weight').sum()).
......7> math('w / f')).
......8> inV().
......9> simplePath()).
.....10> emit().
.....11> local(
.....12> union(
.....13> path().
.....14> by('name').
.....15> by('weight').unfold(),
.....16> sack()).fold()).
.....17> group().
.....18> by(tail(local,2).limit(local,1)).
.....19> by(tail(local).sum()).
.....20> unfold()
==>jerryd=0.768170426065163
==>wyd=0.23182957393483708
==>lisa=0.6666666666666666
==>thomas=0.6491228070175439 第17行的最后一个group步骤使用path结果来计算找到的每个唯一名称的总偏好。若要查看路径,可以在删除group步骤后运行查询。
gremlin> g.withSack(1).V().
......1> has('name','jane').
......2> repeat(outE().
......3> sack(mult).
......4> by(project('w','f').
......5> by('weight').
......6> by(outV().outE().values('weight').sum()).
......7> math('w / f')).
......8> inV().
......9> simplePath()).
.....10> emit().
.....11> local(
.....12> union(
.....13> path().
.....14> by('name').
.....15> by('weight').unfold(),
.....16> sack()).fold())
==>[jane,10,thomas,0.3333333333333333]
==>[jane,20,lisa,0.6666666666666666]
==>[jane,10,thomas,50,wyd,0.11904761904761904]
==>[jane,10,thomas,90,jerryd,0.2142857142857143]
==>[jane,20,lisa,90,thomas,0.3157894736842105]
==>[jane,20,lisa,100,jerryd,0.3508771929824561]
==>[jane,20,lisa,90,thomas,50,wyd,0.11278195488721804]
==>[jane,20,lisa,90,thomas,90,jerryd,0.2030075187969925] Stack Overflow用户
发布于 2020-09-24 19:03:23
这个回答非常优雅,对于涉及到海王星和Python的环境来说也是最好的。我提供第二个参考,以防其他人遇到这个问题。从我看到这个问题的那一刻起,我就只能想象它是用VertexProgram和GraphComputer以OLAP的方式解决的。结果,我很难用其他方式去想它。当然,使用VertexProgram需要像Java这样的JVM语言,并且不会直接与海王星一起工作。我想我最接近的解决方法应该是使用Java,从海王星获取一个subgraph(),然后在本地运行TinkerGraph中的自定义VertexProgram,这样做非常快速。
更普遍的是,如果没有Python/Neptune的需求,根据图形的性质和需要遍历的数据量,将算法转换为VertexProgram并不是一种糟糕的方法。由于在这个主题上没有太多的内容,我想我应该在这里提供代码的核心。这就是它的精髓所在:
@Override
public void execute(final Vertex vertex, final Messenger<Double> messenger, final Memory memory) {
// on the first pass calculate the "total favor" for all vertices
// and pass the calculated current favor forward along incident edges
// only for the "start vertex"
if (memory.isInitialIteration()) {
copyHaltedTraversersFromMemory(vertex);
final boolean startVertex = vertex.value("name").equals(nameOfStartVertrex);
final double initialFavor = startVertex ? 1d : 0d;
vertex.property(VertexProperty.Cardinality.single, FAVOR, initialFavor);
vertex.property(VertexProperty.Cardinality.single, TOTAL_FAVOR,
IteratorUtils.stream(vertex.edges(Direction.OUT)).mapToDouble(e -> e.value("weight")).sum());
if (startVertex) {
final Iterator<Edge> incidents = vertex.edges(Direction.OUT);
memory.add(VOTE_TO_HALT, !incidents.hasNext());
while (incidents.hasNext()) {
final Edge incident = incidents.next();
messenger.sendMessage(MessageScope.Global.of(incident.inVertex()),
(double) incident.value("weight") / (double) vertex.value(TOTAL_FAVOR));
}
}
} else {
// on future passes, sum all the incoming "favor" and add it to
// the "favor" property of each vertex. then once again pass the
// current favor to incident edges. this will keep happening
// until the message passing stops.
final Iterator<Double> messages = messenger.receiveMessages();
final boolean hasMessages = messages.hasNext();
if (hasMessages) {
double adjacentFavor = IteratorUtils.reduce(messages, 0.0d, Double::sum);
vertex.property(VertexProperty.Cardinality.single, FAVOR, (double) vertex.value(FAVOR) + adjacentFavor);
final Iterator<Edge> incidents = vertex.edges(Direction.OUT);
memory.add(VOTE_TO_HALT, !incidents.hasNext());
while (incidents.hasNext()) {
final Edge incident = incidents.next();
messenger.sendMessage(MessageScope.Global.of(incident.inVertex()),
adjacentFavor * ((double) incident.value("weight") / (double) vertex.value(TOTAL_FAVOR)));
}
}
}
}然后以下列方式执行上述操作:
ComputerResult result = graph.compute().program(FavorVertexProgram.build().name("jane").create()).submit().get();
GraphTraversalSource rg = result.graph().traversal();
Traversal elements = rg.V().elementMap();“元素”遍历产生:
{id=0, label=person, ^favor=1.0, name=jane, ^totalFavor=30.0}
{id=2, label=person, ^favor=0.6491228070175439, name=thomas, ^totalFavor=140.0}
{id=4, label=person, ^favor=0.6666666666666666, name=lisa, ^totalFavor=190.0}
{id=6, label=person, ^favor=0.23182957393483708, name=wyd, ^totalFavor=0.0}
{id=8, label=person, ^favor=0.768170426065163, name=jerryd, ^totalFavor=0.0}https://stackoverflow.com/questions/63972067
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号