
尝试使用Scrapy-Splash登录
因为我无法登录到https://www.duif.nl/login,所以我尝试了许多不同的方法,比如selenium,我成功地登录了这些方法,但是没有成功地开始爬行。
现在我试着碰碰运气,但我不能登录:
如果我以飞溅的方式呈现页面,我会看到以下图片:
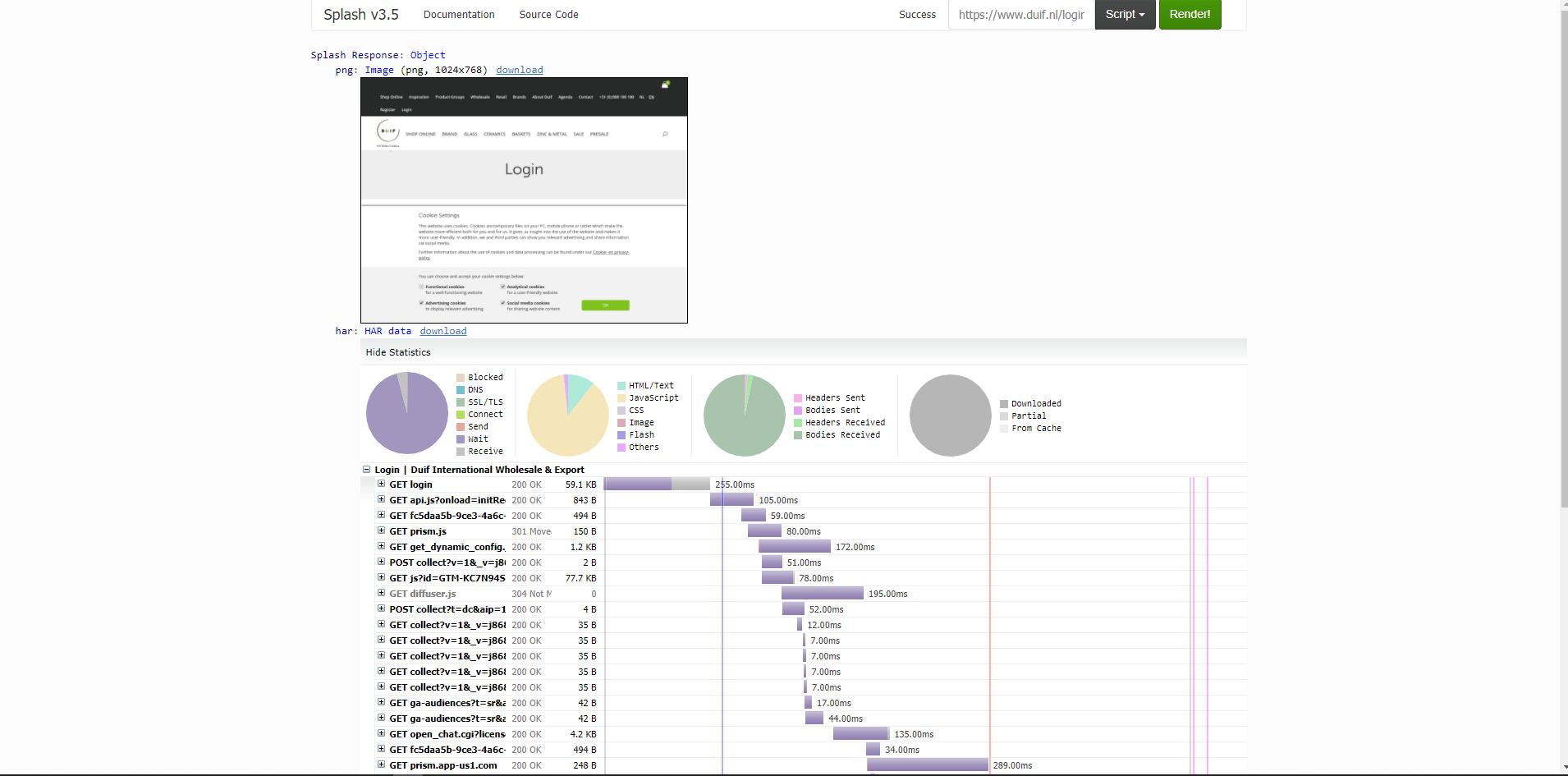
那么,应该有一个loginform,如用户名和密码,但刮刮看不见吗?
我坐在这里,就像一周前的那份遗书,失去了我的生活意志。
我的最后一个问题甚至没有得到一个答案,现在我再试一次。
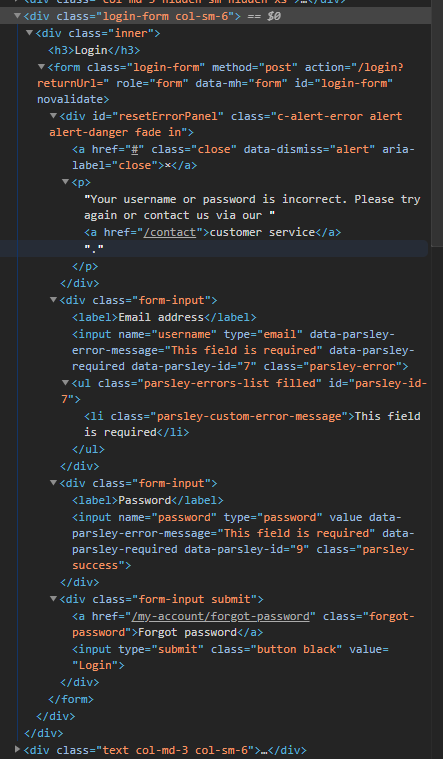
以下是登录表单的html代码:
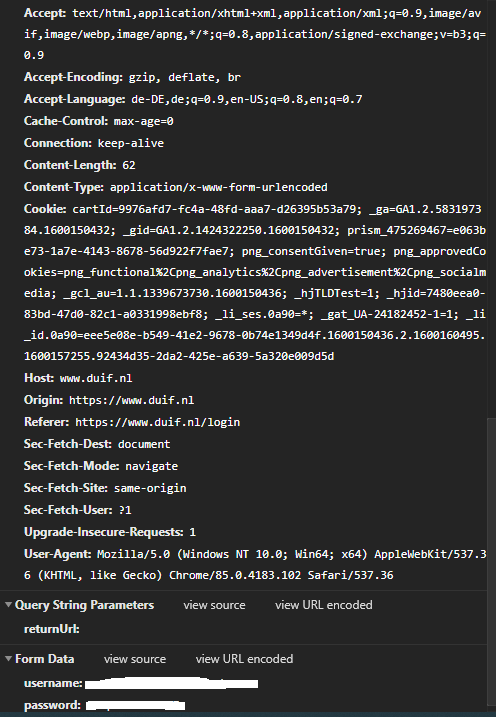
当我登录手册时,我被重定向到"/login?returnUrl=",其中只有以下form_data:
我的代码
# -*- coding: utf-8 -*-
import scrapy
from scrapy_splash import SplashRequest
from scrapy.spiders import CrawlSpider, Rule
from ..items import ScrapysplashItem
from scrapy.http import FormRequest, Request
import csv
class DuifSplash(CrawlSpider):
name = "duifsplash"
allowed_domains = ['duif.nl']
login_page = 'https://www.duif.nl/login'
with open('duifonlylinks.csv', 'r') as f:
reader = csv.DictReader(f)
start_urls = [items['Link'] for items in reader]
def start_requests(self):
yield SplashRequest(
url=self.login_page,
callback=self.parse,
dont_filter=True
)
def parse(self, response):
return FormRequest.from_response(
response,
formdata={
'username' : 'not real',
'password' : 'login data',
}, callback=self.after_login)
def after_login(self, response):
accview = response.xpath('//div[@class="c-accountbox clearfix js-match-height"]/h3')
if accview:
print('success')
else:
print(':(')
for url in self.start_urls:
yield response.follow(url=url, callback=self.parse_page)
def parse_page(self, response):
productpage = response.xpath('//div[@class="product-details col-md-12"]')
if not productpage:
print('No productlink', response.url)
for a in productpage:
items = ScrapysplashItem()
items['SKU'] = response.xpath('//p[@class="desc"]/text()').get()
items['Title'] = response.xpath('//h1[@class="product-title"]/text()').get()
items['Link'] = response.url
items['Images'] = response.xpath('//div[@class="inner"]/img/@src').getall()
items['Stock'] = response.xpath('//div[@class="desc"]/ul/li/em/text()').getall()
items['Desc'] = response.xpath('//div[@class="item"]/p/text()').getall()
items['Title_small'] = response.xpath('//div[@class="left"]/p/text()').get()
items['Price'] = response.xpath('//div[@class="price"]/span/text()').get()
yield items在我的“预工作”中,我爬行了每个内部链接并将其保存到一个..csv文件中,在这里我分析了哪些链接是产品链接,哪些不是产品链接。现在我想知道,如果我打开csv的一个链接,它是否打开了一个经过身份验证的会话?我找不到饼干,这对我来说也很奇怪
更新
我成功地登录了:-)现在我只需要知道cookie存储在哪里
Lua脚本
LUA_SCRIPT = """
function main(splash, args)
splash:init_cookies(splash.args.cookies),
splash:go("https://www.duif.nl/login"),
splash:wait(0.5),
local title = splash.evaljs("document.title"),
return {
title=title,
cookies = splash:get_cookies(),
},
end
"""回答 1
Stack Overflow用户
发布于 2020-09-23 07:35:11
我不认为使用Splash的方式是可行的,因为即使有正常的请求,表单也是存在的:response.xpath('//form[@id="login-form"]')
- There是页面上可用的多个表单,所以您必须指定要基于哪个表单来生成FormRequest.from_response。最好也指定clickdata (所以它会转到'Login',而不是‘忘记密码’)。总之,它应该是这样的:
req = FormRequest.from_response(
response,
formid='login-form',
formdata={
'username' : 'not real',
'password' : 'login data'},
clickdata={'type': 'submit'}
)- 如果您不使用Splash,就不必担心传递cookies -这是由Scrapy处理的。只要确保你没有把COOKIES_ENABLED=False放进你的settings.py
https://stackoverflow.com/questions/64006899
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号