
潘达斯的过滤器-为什么这不起作用?
这是一个基本的问题,所以事先道歉。
我正在使用Pandas,并将数据分组如下:
page_serp_df.groupby([page_serp_df.meta_keywords_1_length]).count()['keyword']这指的是以下内容:
数据帧:page_serp_df
- Grouping by列:meta_keywords_1_length
- Counting与过滤器:关键字列
我不明白的是,为什么过滤条件必须是‘关键字’,即引号中的字符串?例如,这不起作用,而且对我来说非常违背直觉:
page_serp_df.groupby([page_serp_df.meta_keywords_1_length]).count()[page_serp_df.keyword]提前感谢!
回答 1
Stack Overflow用户
发布于 2020-09-23 12:22:00
我认为对于.count()方法返回的内容存在误解。
试着遵循以下示例:
创建一个示例数据框架
df = pd.DataFrame({
'A':[0,1,0,1, 1],
'B':[100,200,300, 400, 500],
'C': [1,2,3,4,5]
})这就是count()方法在groupby之后返回的内容
# similarly to your example I am grouping by A and counting
df.groupby([df.A]).count()
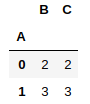
如您所见,count()方法本身返回一个dataframe,其中包含分组列具有相同值的列的每个列值的计数。在此之后,您可以查询一个特定的列形式,返回的count()如下
df.groupby([df.A]).count()['C']但是你的例子中的第二个例子,在我的例子中,它对应于df.groupby([df.A]).count()[df.C]
会抛出一个错误!
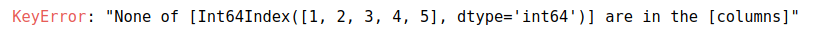
实际上,您可以通过熊猫df.groupby([df.A]).count()查询数据格式(在本例中是Series ),但正如您所知,您需要一个来自df.columns的字符串或列。
您可以检查一下,df.C和'C'是两种非常不同的变量类型。
print(type(df.C))
print(type('C'))
# <class 'pandas.core.series.Series'>
# <class 'str'>如果由于某种原因,您的代码仍然可以与df.C相同,那么可能会有一些意外情况,比如df.C的唯一值是一个具有相同列名的字符串。或者是一些非故意的事。
https://stackoverflow.com/questions/64026930
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号