
GPT2如何在MegatronLM中实现模型并行?
GPT2如何在MegatronLM中实现模型并行?
提问于 2020-09-24 05:29:01
我试图了解MegatronLM的实现细节,它具有模型和数据并行。在他们的站点或他们的研究纸中,他们提到了他们是如何使用层内并行的,这类似于网格TensorFlow。我对一些细节感到困惑。
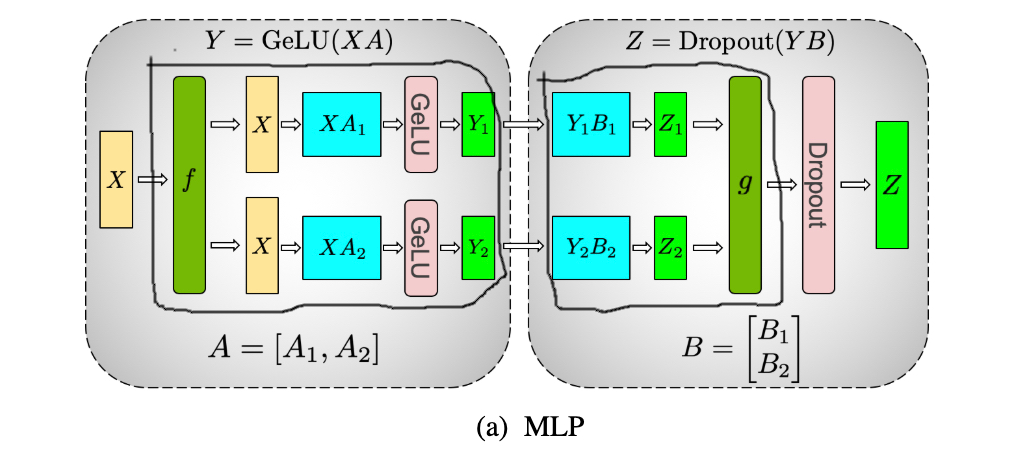
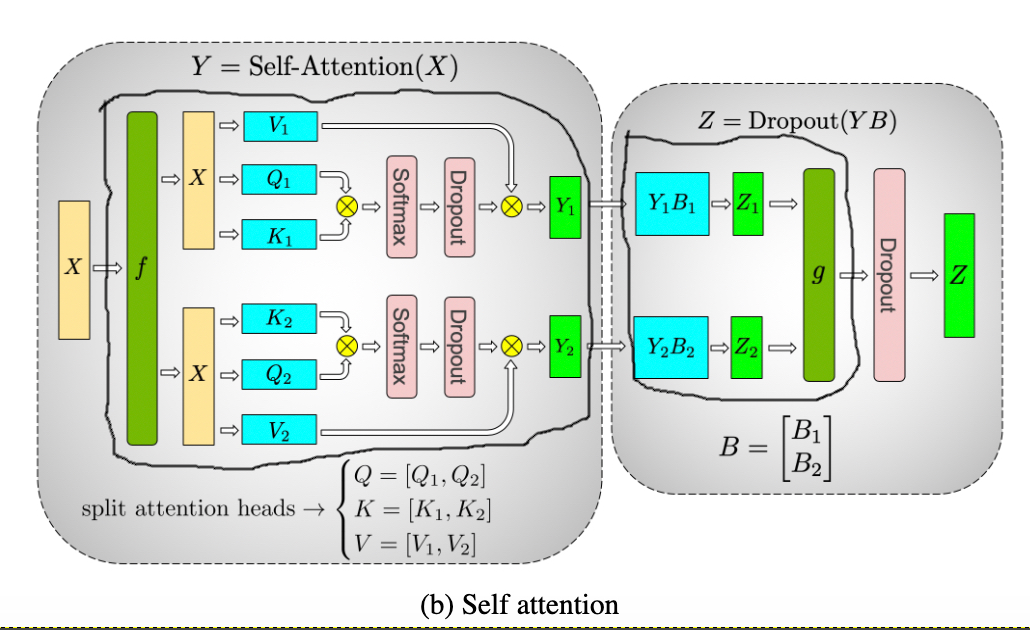
如下图所示,我的理解是,四个红色圆圈内部的计算可以通过层内分裂并行化,但是MLP必须在自我关注之后发生,因此只能同时并行两个红色圈块。文中说,模型平行为8路.我的第一个问题是,是否表明它们将每个块分成4个层内部分(8/2)?。
(8条路除以2块)
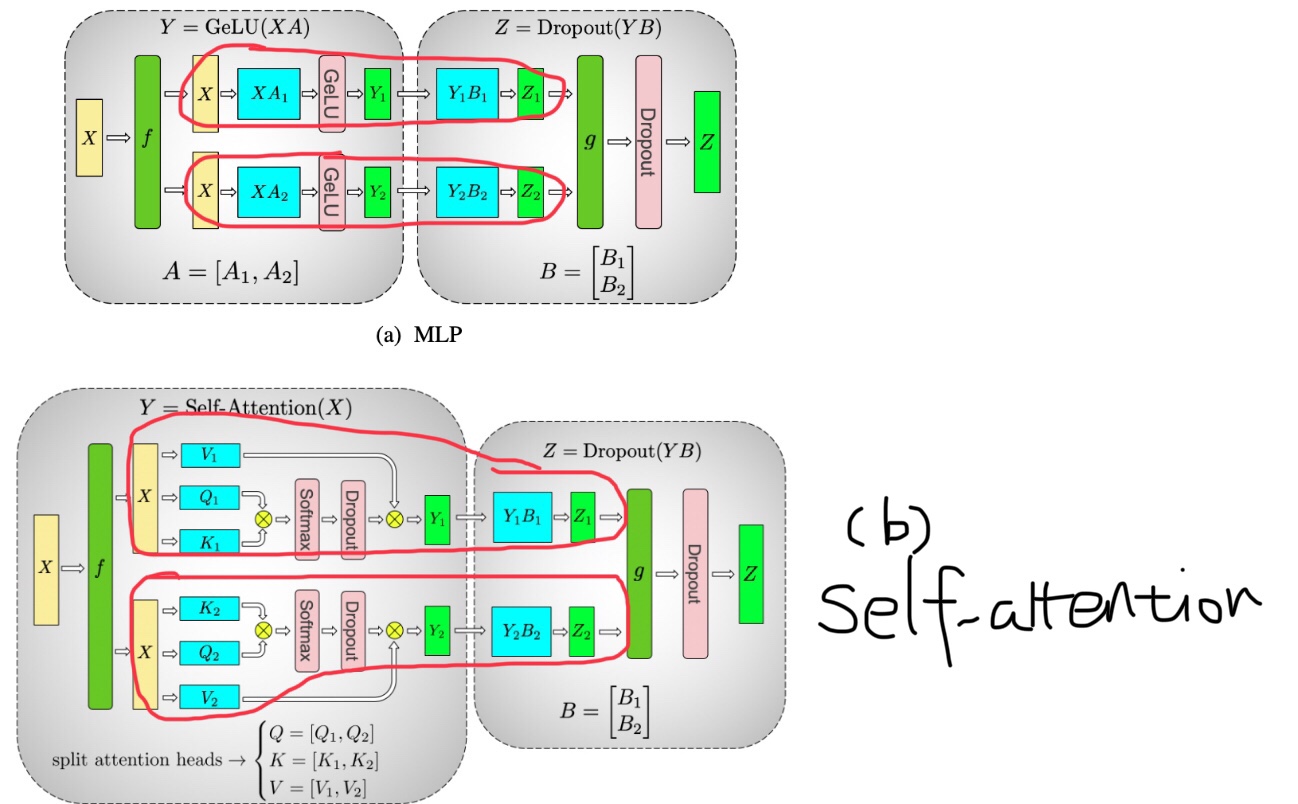
论文中也提到了
为了在自关注层中保持一致的GEMM尺寸,每个注意头的隐藏尺寸保持在96,而头和层的数目变化,以获得10亿到80亿个参数之间的配置。
我的第二个问题是,96隐藏大小指的是什么?
我对分布式训练完全陌生,我可能误解了什么。如对此问题有任何澄清,将不胜感激!谢谢!
回答 1
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64040071
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号