
如何在使用np.nan (.)时区分空字符串、to_excel和None熊猫数据中心的功能?
如何在使用np.nan (.)时区分空字符串、to_excel和None熊猫数据中心的功能?
提问于 2020-09-23 19:53:38
在构建包含np.nan、None和空字符串('')值的Python3.8.3和Pandas1.0.4的数据框架之后
import pandas as pd
import numpy as np
df1 = pd.DataFrame({'b':None,'c':''},index=[0])
df2 = pd.DataFrame({'a':1,'b':1,'c':None},index=[0])
df = pd.concat([df1,df2], axis=0, sort=True)
print(df)数据帧df看起来像
a b c
0 NaN None
0 1.0 1 None现在,我想使用to_excel()函数将这些值存储到Excel中。但是,在运行命令之后
df.to_excel('nan_none_empty.xlsx')结果看起来就像
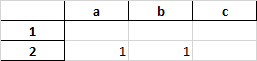
由于np.nan、None和空字符串('')是不可分离的。
可以使用选项''从np.nan和None中分离空字符串( na_rep ),如下所示
df.to_excel('nan_none_empty2.xlsx',na_rep='?')给出结果
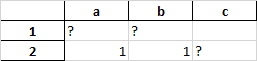
但是,对于这个问题,为了能够在excel(.)函数导出中将np.nan与None分离开来,我似乎已经用完了np.nan。
当将np.nan和None导出到df时,如何将它们巧妙地分开呢?
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-09-23 20:08:53
如果您想要区分不同的空类型,最好的方法是在导出到Excel之前替换值。转换为字符串是确保不合并None、np.NaN、pd.NaT等的一种方法。
df1 = pd.DataFrame({'b':None,'c':''},index=[0])
df2 = pd.DataFrame({'a':1,'b':1,'c':None},index=[0])
df = pd.concat([df1,df2], axis=0, sort=True)
null_map = {'nan': '-',
'None': '?'} # Add the string representation for other types you may need
df = df.applymap(lambda x:
null_map[str(x)]
if str(x) in null_map
else x)
df.to_excel('nan_none_empty2.xlsx')Stack Overflow用户
发布于 2020-09-23 20:09:25
像这样怎么样?:
df = df.applymap(lambda x: str(x) if x in [None, ''] else x)
df.to_excel('nan_none_empty.xlsx',na_rep='np.nan')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64035342
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号