
如何解决熊猫像字符串一样求和行,而不是数字?
如何解决熊猫像字符串一样求和行,而不是数字?
提问于 2020-09-24 16:22:12
对于我的时间序列数据,我试着逐行从列中得到和,但是和是奇怪的。我reset_index表示date,然后逐行接受所有列的求和。有人能告诉我这是怎么回事吗?有什么想法吗?谢谢
我的尝试
下面是我用过的数据和我在这里的尝试:
import pandas as pd
df = pd.read_csv("https://gist.github.com/jerry-shad/ce26357dcabea22f8db307e5d8a625ff#file-ads_df-csv")
df_grp = df.groupby(['date', 'retail_item'])['number_of_stores'].sum().unstack().reset_index('date')
df_grp.set_index('date', inplace=True)
df_grp.loc[:,'Total'] = df_grp.sum(axis=1)但是Total列是被查询的,它应该通过上述尝试得到正确的和,但是输出是错误的。我觉得有点不对劲。有人能告诉我这是怎么回事吗?
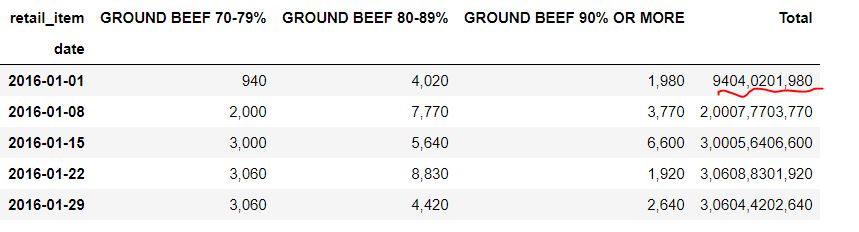
以下是当前的输出:
我也尝试过这样做:
df_grp = df.groupby(['date', 'retail_item']).agg({'number_of_stores': 'sum'})
df_grpe_pcts = df_grp.groupby(level=0).apply(lambda x:100 * x / float(x.sum()))
df_grp = df_grp.diff() / df_grp.shift()主要动机是先通过retail_item的数据分组,然后得到每周所有retail_items的number_of_stores和,然后我想得到百分比和百分比变化对总金额的影响。我怎样才能把这件事纠正过来?在熊猫身上有什么快速的办法吗?谢谢
数据样本
Unnamed: 0,date,region,grade,cut,retail_item,number_of_stores,weighted_avg
40,2016-01-01,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"1,980",4.53
41,2016-01-01,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"4,020",3.65
42,2016-01-01,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,940,2.1
88,2016-01-08,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"3,770",4.76
89,2016-01-08,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"7,770",3.88
90,2016-01-08,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"2,000",2.52
134,2016-01-15,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"6,600",4.69
135,2016-01-15,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"5,640",3.89
136,2016-01-15,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"3,000",2.34
181,2016-01-22,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"1,920",4.79
182,2016-01-22,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"8,830",3.43
183,2016-01-22,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"3,060",2.28
228,2016-01-29,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"2,640",4.2
229,2016-01-29,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"4,420",3.71
230,2016-01-29,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"3,060",2.42
277,2016-02-05,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"4,240",4.87
278,2016-02-05,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"9,820",3.65
279,2016-02-05,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"1,620",2.76
325,2016-02-12,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"4,550",4.88
326,2016-02-12,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"3,540",4.11
327,2016-02-12,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"1,450",2.77
371,2016-02-19,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"3,110",4.84
372,2016-02-19,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"6,270",3.78
373,2016-02-19,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"3,250",2.41
419,2016-02-26,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"3,040",5.04
420,2016-02-26,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"6,420",3.74
421,2016-02-26,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"2,100",2.64
467,2016-03-04,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 90% OR MORE,"3,440",4.74
468,2016-03-04,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 80-89%,"6,040",3.58
469,2016-03-04,NATIONAL,SUMMARY,GRND BEEF,GROUND BEEF 70-79%,"2,350",2.55回答 2
Stack Overflow用户
回答已采纳
发布于 2020-09-24 16:37:21
- 正如您在图像中所看到的,
Total正在将字符串相加在一起。 - 由于
float类型的原因,列不能正确解析为,类型。 - 解析数据的正确方法是在使用
thousands读取数据时使用pandas.read_csv参数。
import pandas as pd
url = 'https://gist.githubusercontent.com/jerry-shad/ce26357dcabea22f8db307e5d8a625ff/raw/1fee3176f5364d0d08b8f97bae781e16c47cea3d/ads_df.csv'
# specify the thousand parameter when reading the data in
df = pd.read_csv(url, parse_dates=['date'], thousands=',')
# drop the unneeded column
df.drop(columns=['Unnamed: 0'], inplace=True)
# groupby
dfg = df.groupby(['date', 'retail_item'])['number_of_stores'].sum().unstack()
# sum rows
dfg['Total'] = dfg.sum(axis=1)
# display(dfg.head())
retail_item GROUND BEEF 70-79% GROUND BEEF 80-89% GROUND BEEF 90% OR MORE Total
date
2016-01-01 940 4020 1980 6940
2016-01-08 2000 7770 3770 13540
2016-01-15 3000 5640 6600 15240
2016-01-22 3060 8830 1920 13810
2016-01-29 3060 4420 2640 10120Stack Overflow用户
发布于 2020-09-24 16:32:48
你在一起加绳子。您可能希望将存储的数量作为整数。在创建df之后立即尝试这一点,并查看代码是否开始工作。
df['number_of_stores'] = df['number_of_stores'].str.replace(',','').astype(int)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64050496
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号