
熊猫在非常大的数据空间上花费太长的时间来旋转桌子/群
熊猫在非常大的数据空间上花费太长的时间来旋转桌子/群
提问于 2020-09-29 09:06:32
我正在处理一个由1 800万行组成的数据格式,其结构如下:
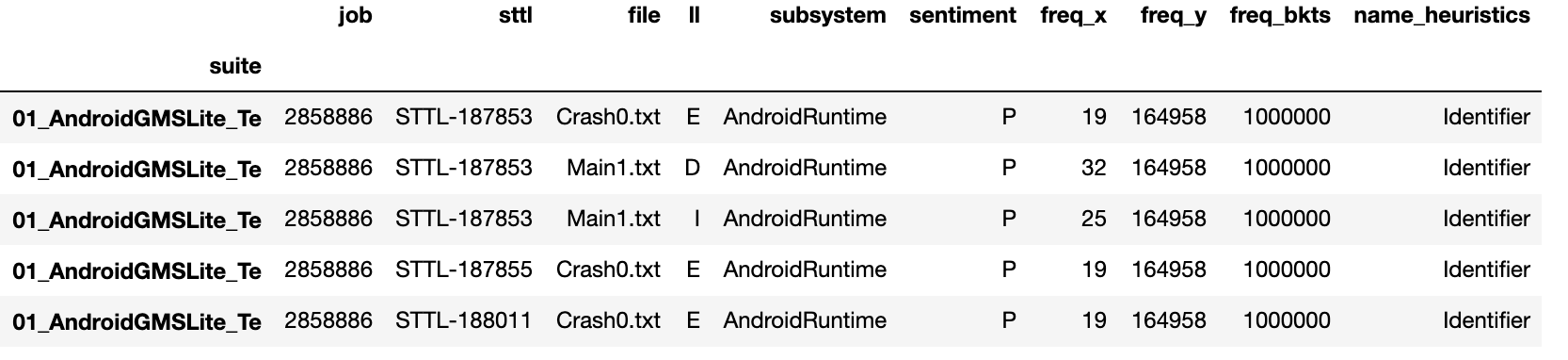
我需要按照name_heuristic获得每个套件的子系统计数(该列有4个值)。因此,我需要为每种类型的name_heuristic提供列的输出,以套件作为索引,并且值将按每列计算子系统数。
我尝试使用pivot_table与以下代码:
df_table = pd.pivot_table(df, index='suite', columns='name_heuristics', values='subsystem', aggfunc=np.sum但是,即使在一个小时后,它还没有完成计算。什么事花了这么长时间,我怎么才能加快速度?我甚至尝试了一种还在运行15分钟的groupby替代方案,并在计算:
df_table = df.groupby(['name_heuristics', 'suite']).agg({'subsystem': np.sum}).unstack(level='name_heuristics').fillna(0)任何帮助都是非常感谢的!我被困在这上面已经好几个小时了。
回答 1
Stack Overflow用户
发布于 2022-09-01 14:01:22
似乎不止一个分类栏会让熊猫崩溃。我对类似问题的解决方案是将目标列的分类转换为对象,使用
- 步骤1
df'col1‘=df’col1‘..astype(’object‘) df'col2’= df'col2'.astype('object')
- 步骤2
df_pivot = pandas.pivot_table(df,列=‘col1’,'col2',index=.
这与数据大小无关..。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64116324
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号