
如何对Python中的多个术语使用正面和负面的前瞻性?
如何对Python中的多个术语使用正面和负面的前瞻性?
提问于 2020-10-01 14:05:00
我有如下所示的数据框架
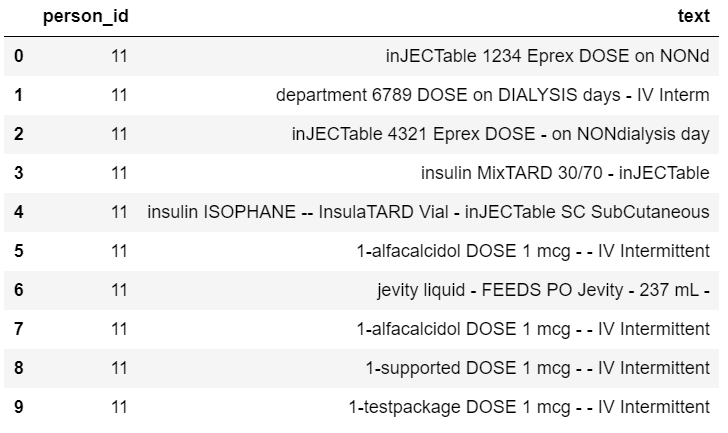
df = pd.DataFrame({'person_id': [11,11,11,11,11,11,11,11,11,11],
'text':['inJECTable 1234 Eprex DOSE 4000 units on NONd',
'department 6789 DOSE 8000 units on DIALYSIS days - IV Interm',
'inJECTable 4321 Eprex DOSE - 3 times/wk on NONdialysis day',
'insulin MixTARD 30/70 - inJECTable 46 units',
'insulin ISOPHANE -- InsulaTARD Vial - inJECTable 56 units SC SubCutaneous',
'1-alfacalcidol DOSE 1 mcg - 3 times a week - IV Intermittent',
'jevity liquid - FEEDS PO Jevity - 237 mL - 1 times per day',
'1-alfacalcidol DOSE 1 mcg - 3 times per week - IV Intermittent',
'1-supported DOSE 1 mcg - 1 time/day - IV Intermittent',
'1-testpackage DOSE 1 mcg - 1 time a day - IV Intermittent']})我想删除46 units、3 times a week、3 times per week、1 time/day等模式下的单词/字符串。
我读到了积极和消极的展望前后。
所以,试着像下面这样的
[^([0-9\s]*(?=units))] #to remove terms like `46 units` from the string
[^[0-9\s]*(?=times)(times a day)] # don't know how to make this work for all time variants时间变体如:3 times a day、3 time/wk、3 times per day、3 times a month、3 times/month等。
基本上,我希望我的输出如下(去掉像xx单位,某日时间,每周xx次,xx时间/日,xx时间/周,xx时间/周,xx次每周,等等)
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-10-01 14:14:23
您可以考虑这样的模式
\s*\d+\s*(?:units?|times?(?:\s+(?:a|per)\s+|\s*/\s*)(?:d(?:ay)?|w(?:ee)?k|month|y(?:ea)?r?))注意事项:\d+匹配一个或多个数字。如果您需要匹配任何数字,请考虑以您期望的格式对数字使用其他模式,例如,请参见查找十进制/浮点数的正则表达式?。
模式细节
\s*-零或更多空格字符\d+-一个或多个数字\s*-零或多个空白空间(?:units?|times?(?:\s+(?:a|per)\s+|\s*/\s*)(?:d(?:ay)?|w(?:ee)?k|month|y(?:ea)?r?))-非捕获组匹配:units?-unit或units|-或times?-time或times(?:\s+(?:a|per)\s+|\s*/\s*)-a或per包含1+空格,或/包含0+空格(?:d(?:ay)?|w(?:ee)?k|month|y(?:ea)?r?)-d或day,wk或week,month,或month
如果只需要匹配整个单词,请使用单词边界,\b
\s*\b\d+\s*(?:units?|times?(?:\s+(?:a|per)\s+|\s*/\s*)(?:d(?:ay)?|w(?:ee)?k|month|y(?:ea)?r?))\b在潘达斯,使用
df['text'] = df['text'].str.replace(r'\s*\b\d+\s*(?:units?|times?(?:\s+(?:a|per)\s+|\s*/\s*)(?:d(?:ay)?|w(?:ee)?k|month|y(?:ea)?r?))\b', '')页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64157077
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号