
正则表达式,用于在多个模式之前找到一个数字序列,放入一个新列(Python,Pandas)。
正则表达式,用于在多个模式之前找到一个数字序列,放入一个新列(Python,Pandas)。
提问于 2020-10-02 06:23:07
这是我的示例数据
import pandas as pd
import re
cars = pd.DataFrame({'Engine Information': {0: 'Honda 2.4L 4 cylinder 190 hp 162 ft-lbs',
1: 'Aston Martin 4.7L 8 cylinder 420 hp 346 ft-lbs',
2: 'Dodge 5.7L 8 Cylinder 390hp 407 ft-lbs',
3: 'MINI 1.6L 4 Cylinder 118 hp 114 ft-lbs',
4: 'Ford 5.0L 8 Cylinder 360hp 380 ft-lbs FFV',
5: 'GMC 6.0L 8 Cylinder 352 hp 382 ft-lbs'},
'HP': {0: None, 1: None, 2: None, 3: None, 4: None, 5: None}})这是我的想要的输出
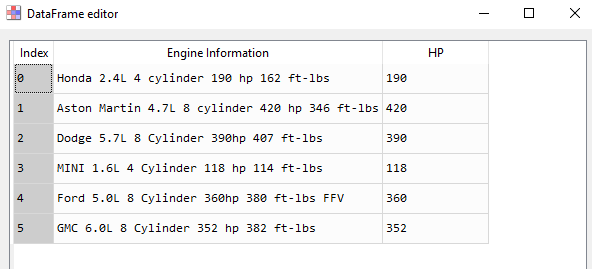
我创建了一个名为“HP”的新列,在该列中,我希望从原始列(“引擎信息”)中提取马力图。
下面是我尝试做这个的代码
cars['HP'] = cars['Engine Information'].apply(lambda x: re.match(r'\\d+(?=\\shp|hp)', str(x)))我的想法是,我想要调整匹配的模式:‘在'hp’或‘hp’之前出现的一系列数字。这是因为一些单元格在数字和hp之间没有“空格”,如我的例子所示。
我确信正则表达式是正确的,因为我已经在R中成功地完成了类似的过程,但是,我尝试了一些函数,如str.extract、re.findall、re.search、re.match。返回错误或“无”值(如示例所示)。所以我有点迷路了。
谢谢!
回答 3
Stack Overflow用户
回答已采纳
发布于 2020-10-02 07:05:43
您可以使用str.extract
cars['HP'] = cars['Engine Information'].str.extract(r'(\d+)\s*hp\b', flags=re.I)详细信息
(\d+)\s*hp\b--将一个或多个数字匹配并捕获到第1组中,然后将0或多个空白空间(\s*)和hp(由于flags=re.I以不区分大小写的方式)作为一个整体来匹配(因为\b标记单词boundary)str.extract只在模式中有捕获组时才返回捕获的值,因此hp和空格不是结果的一部分。)
Python演示结果:
>>> cars
Engine Information HP
0 Honda 2.4L 4 cylinder 190 hp 162 ft-lbs 190
1 Aston Martin 4.7L 8 cylinder 420 hp 346 ft-lbs 420
2 Dodge 5.7L 8 Cylinder 390hp 407 ft-lbs 390
3 MINI 1.6L 4 Cylinder 118 hp 114 ft-lbs 118
4 Ford 5.0L 8 Cylinder 360hp 380 ft-lbs FFV 360
5 GMC 6.0L 8 Cylinder 352 hp 382 ft-lbs 352Stack Overflow用户
发布于 2020-10-02 07:12:43
有几个问题:
re.match只查看字符串的开头,如果您的模式可能出现在- 无法转义的地方,则使用
re.search,如果您使用了原始字符串,即'\\d hp'或r'\d hp'--原始字符串可以帮助您避免使用匹配的组。你只是在搜索,但没有交出找到的小组。re.search(rex, string)[0] - you为您提供了一个复杂的对象(匹配对象),您可以从中提取所有组,例如,
re.search(rex, string)[0] - you必须将访问包装在一个单独的函数中,因为您必须在访问组之前检查是否有匹配。如果不这样做,异常可能会在
cars['Engine Information'].str.extract(r'(\d+) ?hp')
中间停止应用进程,
- 的应用是缓慢的;使用提取:
- 之类的向量化函数。
您的方法应该在以下方面发挥作用:
def match_horsepower(s):
m = re.search(r'(\d+) ?hp', s)
return int(m[1]) if m else None
cars['HP'] = cars['Engine Information'].apply(match_horsepower)Stack Overflow用户
发布于 2020-10-02 06:53:40
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64166976
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号