
尝试用pyhf编写一个教学示例。
我试图了解更多关于pyhf的知识,我对目标的理解可能是有限的。我很想把我的HEP数据放在根之外,但我可能会把期望强加在pyhf上,而这并不是作者所期望的。
我想给自己写个“你好世界”的例子,但我可能不知道自己在做什么。我的误解也可能是我的统计知识的空白。
在序言中,让我解释一下我想要探索的东西。
我有一些观察到的事件集,我计算了一些可观测的,并对这些数据做了一个二进制直方图。我假设有两个物理过程,我称之为信号和背景。我为这些过程生成了一些Monte样本,理论上的事件总数接近,但不是我所观察到的。
我想:
- 将数据与这两个过程假设相匹配。
- 从fit中获取每个进程的事件数的最优值。
- 得到这些拟合值的不确定性。
- 如果适当,计算信号事件数量的上限。
我的初学者代码在下面,我所做的只是一个ML fit,但我不知道该去哪里。我知道它不适合做我想做的事情,但是我在RTD上找到的例子中我迷失了方向。我肯定是我,这不是对文件的批评。
import pyhf
import numpy as np
import matplotlib.pyplot as plt
nbins = 15
# Generate a background and signal MC sample`
MC_signal_events = np.random.normal(5,1.0,200)
MC_background_events = 10*np.random.random(1000)
signal_data = np.histogram(MC_signal_events,bins=nbins)[0]
bkg_data = np.histogram(MC_background_events,bins=nbins)[0]
# Generate an observed dataset with a slightly different
# number of events
signal_events = np.random.normal(5,1.0,180)
background_events = 10*np.random.random(1050)
observed_events = np.array(signal_events.tolist() + background_events.tolist())
observed_sample = np.histogram(observed_events,bins=nbins)[0]
# Plot these samples, if you like
plt.figure(figsize=(12,4))
plt.subplot(1,3,1)
plt.hist(observed_events,bins=nbins,label='Observations')
plt.legend()
plt.subplot(1,3,2)
plt.hist(MC_signal_events,bins=nbins,label='MC signal')
plt.legend()
plt.subplot(1,3,3)
plt.hist(MC_background_events,bins=nbins,label='MC background')
plt.legend()
# Use a very naive estimate of the background
# uncertainties
bkg_uncerts = np.sqrt(bkg_data)
print("Defining the PDF.......")
pdf = pyhf.simplemodels.hepdata_like(signal_data=signal_data.tolist(), \
bkg_data=bkg_data.tolist(), \
bkg_uncerts=bkg_uncerts.tolist())
print("Fit.......")
data = pyhf.tensorlib.astensor(observed_sample.tolist() + pdf.config.auxdata)
bestfit_pars, twice_nll = pyhf.infer.mle.fit(data, pdf, return_fitted_val=True)
print(bestfit_pars)
print(twice_nll)
plt.show()回答 2
Stack Overflow用户
发布于 2020-10-09 03:55:12
注意:这个答案基于pyhfv0.5.2。
好吧,看起来你已经成功地找到了大部分的大碎片。然而,有两种不同的方法来实现这一点,这取决于您喜欢如何设置。在这两种情况下,我假设你想要一个不受约束的合身而你想.
- 将您的signal+background模型与观测数据相匹配
- 将背景模型与观测数据相匹配
首先,让我们简要讨论不确定性。目前,我们默认使用numpy作为张量背景,scipy作为优化器。见文件:
然而,scipy优化器现在的一个不幸的缺点是它不能返回不确定性。在fit之前,您需要在代码中的任何地方(虽然我们通常建议尽早)使用minuit优化器:
pyhf.set_backend('numpy', 'minuit')这样你就可以得到相关矩阵的优点,拟合参数的不确定性,以及恒河--等等。我们也在努力让这件事变得一致,但现在还没有准备好。
所有优化都通过我们的optimizer API进行,您目前可以通过文档中的混合在这里查看这些API。具体来说,签名是
minimize(
objective,
data,
pdf,
init_pars,
par_bounds,
fixed_vals=None,
return_fitted_val=False,
return_result_obj=False,
do_grad=None,
do_stitch=False,
**kwargs)这里有很多选择。让我们专注于这样一个事实,即我们可以传递的关键字参数之一是return_uncertainties,它将通过为您想要的拟合参数不确定性添加一列来改变最佳匹配参数。
1. Signal+Background
在这种情况下,我们只想使用默认模型
result, twice_nll = pyhf.infer.mle.fit(
data,
pdf,
return_uncertainties=True,
return_fitted_val=True
)
bestfit_pars, errors = result.T2.仅限于背景
在这种情况下,我们需要关掉信号。我们这样做的方法是将兴趣参数(POI)固定为0.0。然后,我们可以以类似的方式获得只适用于背景的模型的拟合参数,但使用fixed_poi_fit而不是无约束的fit:
result, twice_nll = pyhf.infer.mle.fixed_poi_fit(
0.0,
data,
pdf,
return_uncertainties=True,
return_fitted_val=True
)
bestfit_pars, errors = result.T请注意,这是一种非常简单的快速执行以下无约束匹配的方法
bkg_params = pdf.config.suggested_init()
fixed_params = pdf.config.suggested_fixed()
bkg_params[pdf.config.poi_index] = 0.0
fixed_params[pdf.config.poi_index] = True
result, twice_nll = pyhf.infer.mle.fit(
data,
pdf,
init_pars=bkg_params,
fixed_params=fixed_params,
return_uncertainties=True,
return_fitted_val=True
)
bestfit_pars, errors = result.T希望这能澄清更多的事情!
Stack Overflow用户
发布于 2020-10-13 23:33:35
Giordon的解决方案应该回答您所有的问题,但是我想我也应该编写代码来解决我们所能解决的所有问题。我还冒昧地改变了你的一些值,这样信号就不那么强了,所以观测到的CLs值离巴西波段的右边不远(结果并不明显是错的,但在那个时候讨论使用发现测试统计量,然后设定限制可能更有意义。):)
环境
对于本例,我将设置一个干净的Python3虚拟环境,然后安装依赖项(这里我们将使用pyhf v0.5.2)
$ python3 -m venv "${HOME}/.venvs/question"
$ . "${HOME}/.venvs/question/bin/activate"
(question) $ cat requirements.txt
pyhf[minuit,contrib]~=0.5.2
black
(question) $ python -m pip install -r requirements.txt代码
虽然信号事件的数量和背景事件都很难得到最佳拟合值,但我们可以进行推断,得到信号强度的最佳拟合值。下面的代码块(因为可视化而很长)应该解决问题的所有要点。
# answer.py
import numpy as np
import pyhf
import matplotlib.pyplot as plt
import pyhf.contrib.viz.brazil
# Goals:
# - Fit the model to the observed data
# - Infer the best fit signal strength given the model
# - Get the uncertainties on the best fit signal strength
# - Calculate an 95% CL upper limit on the signal strength
def plot_hist(ax, bins, data, bottom=0, color=None, label=None):
bin_width = bins[1] - bins[0]
bin_leftedges = bins[:-1]
bin_centers = [edge + bin_width / 2.0 for edge in bin_leftedges]
ax.bar(
bin_centers, data, bin_width, bottom=bottom, alpha=0.5, color=color, label=label
)
def plot_data(ax, bins, data, label="Data"):
bin_width = bins[1] - bins[0]
bin_leftedges = bins[:-1]
bin_centers = [edge + bin_width / 2.0 for edge in bin_leftedges]
ax.scatter(bin_centers, data, color="black", label=label)
def invert_interval(test_mus, hypo_tests, test_size=0.05):
# This will be taken care of in v0.5.3
cls_obs = np.array([test[0] for test in hypo_tests]).flatten()
cls_exp = [
np.array([test[1][idx] for test in hypo_tests]).flatten() for idx in range(5)
]
crossing_test_stats = {"exp": [], "obs": None}
for cls_exp_sigma in cls_exp:
crossing_test_stats["exp"].append(
np.interp(
test_size, list(reversed(cls_exp_sigma)), list(reversed(test_mus))
)
)
crossing_test_stats["obs"] = np.interp(
test_size, list(reversed(cls_obs)), list(reversed(test_mus))
)
return crossing_test_stats
def main():
np.random.seed(0)
pyhf.set_backend("numpy", "minuit")
observable_range = [0.0, 10.0]
bin_width = 0.5
_bins = np.arange(observable_range[0], observable_range[1] + bin_width, bin_width)
n_bkg = 2000
n_signal = int(np.sqrt(n_bkg))
# Generate simulation
bkg_simulation = 10 * np.random.random(n_bkg)
signal_simulation = np.random.normal(5, 1.0, n_signal)
bkg_sample, _ = np.histogram(bkg_simulation, bins=_bins)
signal_sample, _ = np.histogram(signal_simulation, bins=_bins)
# Generate observations
signal_events = np.random.normal(5, 1.0, int(n_signal * 0.8))
bkg_events = 10 * np.random.random(int(n_bkg + np.sqrt(n_bkg)))
observed_events = np.array(signal_events.tolist() + bkg_events.tolist())
observed_sample, _ = np.histogram(observed_events, bins=_bins)
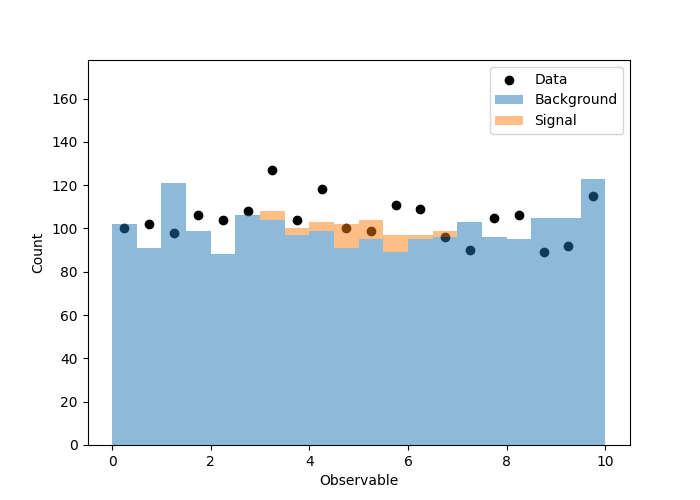
# Visualize the simulation and observations
fig, ax = plt.subplots()
fig.set_size_inches(7, 5)
plot_hist(ax, _bins, bkg_sample, label="Background")
plot_hist(ax, _bins, signal_sample, bottom=bkg_sample, label="Signal")
plot_data(ax, _bins, observed_sample)
ax.legend(loc="best")
ax.set_ylim(top=np.max(observed_sample) * 1.4)
ax.set_xlabel("Observable")
ax.set_ylabel("Count")
fig.savefig("components.png")
# Build the model
bkg_uncerts = np.sqrt(bkg_sample)
model = pyhf.simplemodels.hepdata_like(
signal_data=signal_sample.tolist(),
bkg_data=bkg_sample.tolist(),
bkg_uncerts=bkg_uncerts.tolist(),
)
data = pyhf.tensorlib.astensor(observed_sample.tolist() + model.config.auxdata)
# Perform inference
fit_result = pyhf.infer.mle.fit(data, model, return_uncertainties=True)
bestfit_pars, par_uncerts = fit_result.T
print(
f"best fit parameters:\
\n * signal strength: {bestfit_pars[0]} +/- {par_uncerts[0]}\
\n * nuisance parameters: {bestfit_pars[1:]}\
\n * nuisance parameter uncertainties: {par_uncerts[1:]}"
)
# Perform hypothesis test scan
_start = 0.0
_stop = 5
_step = 0.1
poi_tests = np.arange(_start, _stop + _step, _step)
print("\nPerforming hypothesis tests\n")
hypo_tests = [
pyhf.infer.hypotest(
mu_test,
data,
model,
return_expected_set=True,
return_test_statistics=True,
qtilde=True,
)
for mu_test in poi_tests
]
# Upper limits on signal strength
results = invert_interval(poi_tests, hypo_tests)
print(f"Observed Limit on µ: {results['obs']:.2f}")
print("-----")
for idx, n_sigma in enumerate(np.arange(-2, 3)):
print(
"Expected {}Limit on µ: {:.3f}".format(
" " if n_sigma == 0 else "({} σ) ".format(n_sigma),
results["exp"][idx],
)
)
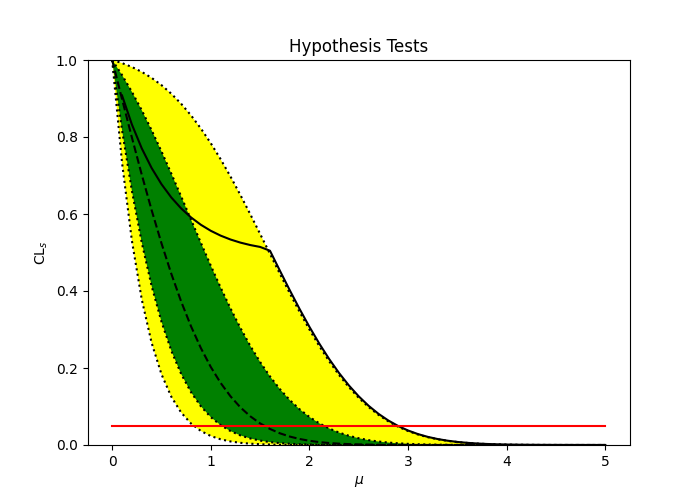
# Visualize the "Brazil band"
fig, ax = plt.subplots()
fig.set_size_inches(7, 5)
ax.set_title("Hypothesis Tests")
ax.set_ylabel(r"$\mathrm{CL}_{s}$")
ax.set_xlabel(r"$\mu$")
pyhf.contrib.viz.brazil.plot_results(ax, poi_tests, hypo_tests)
fig.savefig("brazil_band.png")
if __name__ == "__main__":
main()当运行时
(question) $ python answer.py
best fit parameters:
* signal strength: 1.5884737977889158 +/- 0.7803435235862329
* nuisance parameters: [0.99020988 1.06040191 0.90488207 1.03531383 1.09093327 1.00942088
1.07789316 1.01125627 1.06202964 0.95780043 0.94990993 1.04893286
1.0560711 0.9758487 0.93692481 1.04683181 1.05785515 0.92381263
0.93812855 0.96751869]
* nuisance parameter uncertainties: [0.06966439 0.07632218 0.0611428 0.07230328 0.07872258 0.06899675
0.07472849 0.07403246 0.07613661 0.08606657 0.08002775 0.08655314
0.07564512 0.07308117 0.06743479 0.07383134 0.07460864 0.06632003
0.06683251 0.06270965]
Performing hypothesis tests
/home/stackoverflow/.venvs/question/lib/python3.7/site-packages/pyhf/infer/calculators.py:229: RuntimeWarning: invalid value encountered in double_scalars
teststat = (qmu - qmu_A) / (2 * self.sqrtqmuA_v)
Observed Limit on µ: 2.89
-----
Expected (-2 σ) Limit on µ: 0.829
Expected (-1 σ) Limit on µ: 1.110
Expected Limit on µ: 1.542
Expected (1 σ) Limit on µ: 2.147
Expected (2 σ) Limit on µ: 2.882
如果你还有什么问题,请告诉我们!
https://stackoverflow.com/questions/64257667
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号