
API web数据捕获
我正试图为一个分析项目提取高尔夫数据。
TL;DR总结:我是否应该使用我在网络控制台中找到的API使用循环?
我想要获得6或7个统计类别的数据,按年份(2015年至今),最好是按赛事,以更好地分类球员的比赛表现。基本网址是:https://www.pgatour.com/stats
该网站有许多页面,一旦您单击特定的stat页面,它就有三个下拉字段:季节(包含年份)、时间段(仅为锦标赛或YTD)和锦标赛(锦标赛名称)。
找到可能隐藏的API:
https://statdata-api-prod.pgatour.com/api/clientfile/YTDEventStats?T_CODE=r&STAT_ID=02671&YEAR=2021&format=json但它只有最近一届锦标赛的数据,而且不太干净(没有表数据的stat类别标题):
我可以通过更改Stat ID=value和年份来调整JSON。因此,这是一个选项,但我必须弄清楚如何将锦标赛id号和锦标赛统计数据添加为键值对。
一个例子的URL看起来是这样的:https://www.pgatour.com/content/pgatour/stats/stat.02674.y2017.eon.t030.html eon只允许统计锦标赛(eoff是用于YTD的),而t030是锦标赛的标记。
我是否应该创建循环并更改年份、锦标赛编号和stat编号,并在JSON中获取所有信息并尝试将其转换为df?
- 如何在JSON url中将锦标赛和eon限定符添加为键值对?
- ,这是否可行?
或者我应该把它刮起来,尝试使用HTML (可能的话,可以捕获stat行标题)?
包含网站中一个表的快照
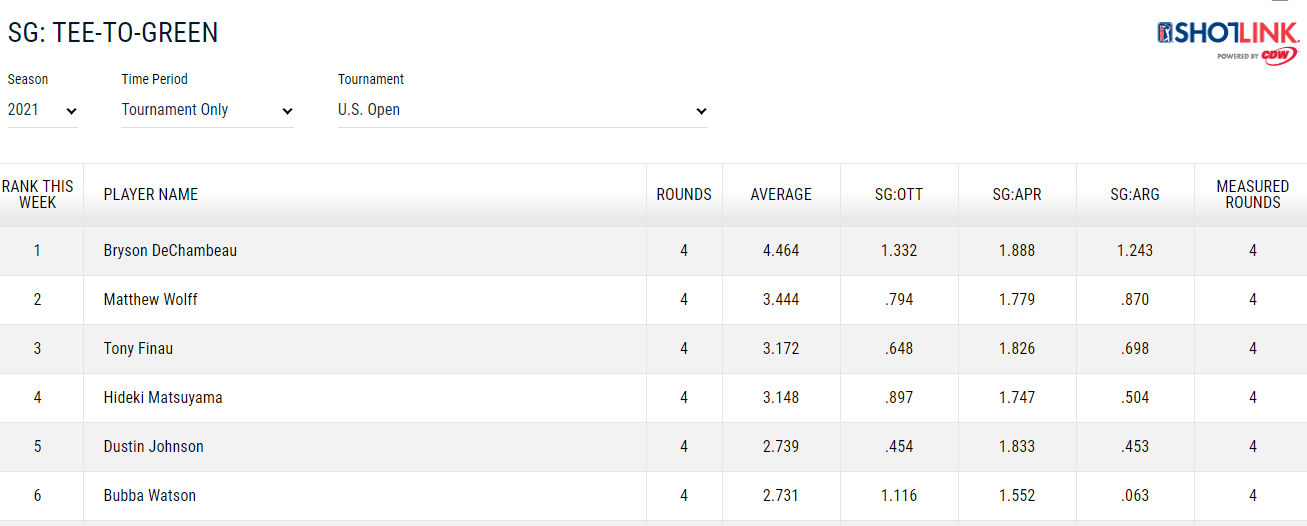
回答 1
Stack Overflow用户
发布于 2020-10-23 14:49:26
我会去刮擦,因为网址本身给你更多的控制权,你想要什么。此外,你也可以很容易地获得有关熊猫的表格数据。
例如:
import requests
import pandas as pd
headers = {
"accept": "application/json, text/javascript, */*; q=0.01",
"accept-encoding": "gzip, deflate, br",
"accept-language": "en-GB,en-US;q=0.9,en;q=0.8",
"user-agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.99 Safari/537.36",
"x-requested-with": "XMLHttpRequest",
}
url = "https://www.pgatour.com/content/pgatour/stats/stat.02674.y2017.eon.t030.html"
html = requests.get(url).text
df = pd.read_html(html, flavor="html5lib")
df = pd.concat(df).drop([0, 1, 2], axis=1)
df.to_csv("golf.csv", index=False)给你这个:
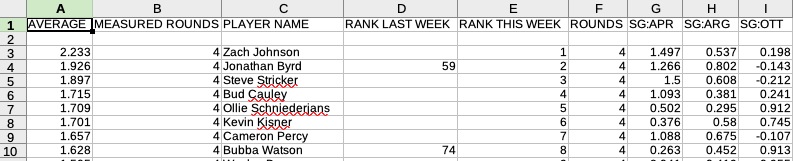
然后,您可以继续交换URL或修改URL的stat.、y和eon部分,以获得不同的统计信息。例如,2018年美国开放- https://www.pgatour.com/content/pgatour/stats/stat.02674.y2017.eon.t030.html
https://stackoverflow.com/questions/64501788
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号