
为什么我的注意力模型比非注意力模型差?
我的任务是把英语句子转换成德语句子。我第一次用普通的编解码网络做了这件事,得到了相当好的结果。然后,我试图用和以前一样的精确模型来解决相同的任务,但是在其中使用了Bahdanau注意。并且,该模型的性能优于有注意的模型。
模型的损失在没有注意的情况下从大约8.0下降到1.4在5个时代,到1.0在10个时代,损失仍然在减少,但以一个较慢的速度。
该模型失去了关注,从大约8.0到2.6在5个时代,并没有得到更多的了解。
由于验证损失在这两种模型中也在减少,所以没有一种模型过拟合。
每个英语句子中有47个单词(填充物后),每个德语句子中有54个单词(填空后)。我有7000英语和7000德语句子在培训集和3000在验证集。
我尝试了几乎所有的东西:不同的学习率,不同的优化器,不同的批处理大小,不同的激活函数,我在模型中使用了不同的批处理和层归一化,以及不同数量的LSTM单元用于编解码,但是没有什么区别,除了归一化和增加数据,其中损失下降到大约1.5,然后再次停止学习!
为什么会发生这种事?为什么巴哈瑙关注的模式失败了,而没有任何关注的模式却表现得很好?
编辑1-我试着在注意前、注意后和注意前后应用LayerNormalization。每个病例的结果大致相同。但是,这一次,在5个时代,损失从8.0左右下降到2.1,而且也没有学到多少东西。但大部分的学习是在一个时期进行的,到了1世纪末,损失约为2.6,下一个时期达到2.1,然后又没有学到很多东西。
尽管如此,没有任何注意的模型仍然优于同时关注和LayerNormzalization的模型。这是什么原因?我得到的结果有可能吗?一个普通的编解码网络,没有任何规格化,没有丢包层,怎么能比注意和LayerNormalization模型的性能更好呢?
编辑2-我尝试增加数据(我做了7倍于前一个),这一次,这两个模型的性能有了很大的提高。但是,没有注意的模型比有注意的模型表现得更好。为什么会发生这种情况?
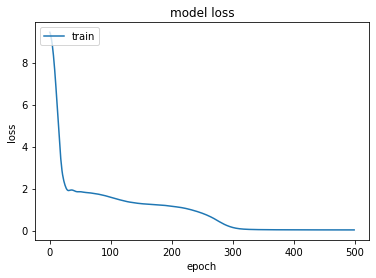
编辑3-我试着调试模型,首先从整个训练数据集中传递一个样本。损失开始时约为9.0,目前正在减少并收敛于0。然后,我尝试通过传递两个样本,损失再次开始在9.0左右,但这一次,它只是徘徊在1.5到2.0之间的前400个时代,然后慢慢减少。这是当我仅用两个样本训练它时,损失是如何减少的:
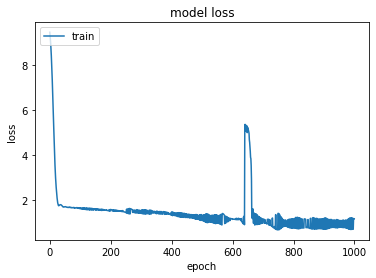
这是当我仅用一个样本训练它时,损失是如何减少的:
回答 1
Stack Overflow用户
发布于 2020-10-31 12:46:29
谢谢大家的帮助..。是个执行问题..。解决这个问题,使注意力模型比正常的编解码模型表现得更好!
https://stackoverflow.com/questions/64521775
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号