
火花结构化流媒体应用程序中的死执行者
火花结构化流媒体应用程序中的死执行者
提问于 2020-10-27 06:01:43
我有一个简单的流媒体工作,它从卡夫卡主题中提取数据并将其推送到S3。
df2 = parsed_df \
.coalesce(1)\
.writeStream.format("parquet")\
.option("checkpointLocation", "<s3location>")\
.option("path","s3location")\
.partitionBy("dt")\
.outputMode("Append")\
.trigger(processingTime='150 seconds')\
.start()触发时间是150秒。我的星火配置在此工作的下面。
"driverMemory": "6G",
"driverCores": 1,
"executorCores": 1,
"executorMemory": "3G",
{
"spark.dynamicAllocation.initialExecutors": "3",
"spark.dynamicAllocation.maxExecutors": "12",
"spark.driver.maxResultSize": "4g",
"spark.sql.session.timeZone":"UTC",
"spark.executor.memoryOverhead": "1g",
"spark.driver.memoryOverhead": "2g",
"spark.dynamicAllocation.enabled": "true",
"spark.rpc.message.maxSize": "1024",
"spark.streaming.receiver.maxRate": "4000",
"spark.port.maxRetries" : "100",
"spark.jars.packages": "org.apache.spark:spark-sql-kafka-0-10_2.11:2.4.4,org.apache.spark:spark-streaming-kafka-0-10-assembly_2.12:2.4.4"
}工作进展顺利。但是当我检查我的星星之火时,我看到了很多死去的执行者。
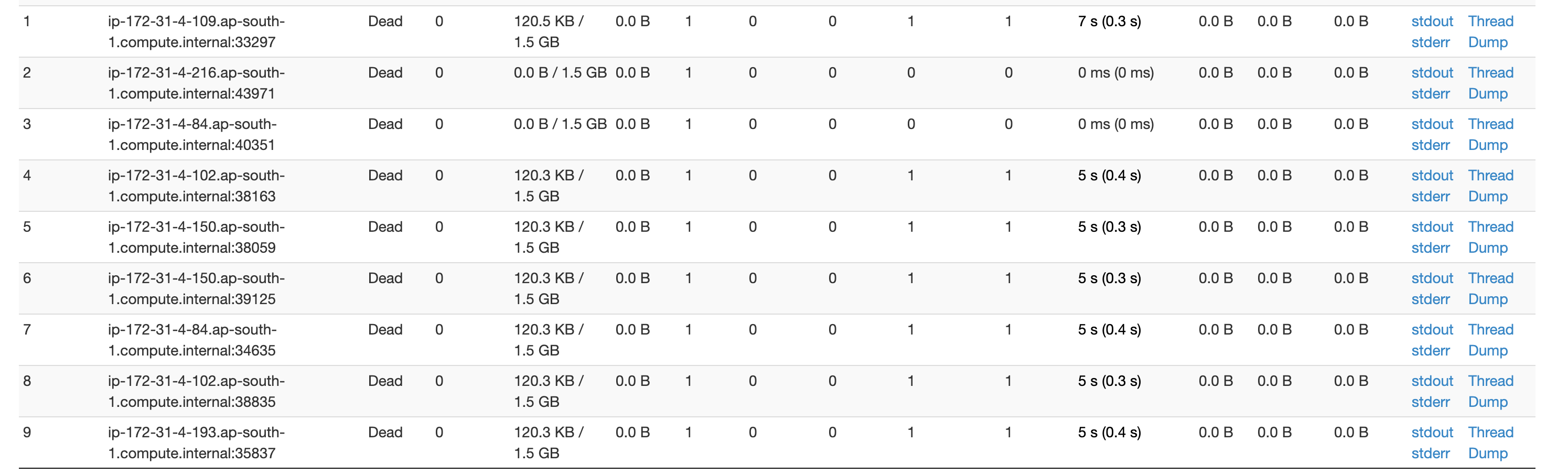
这些死去的刽子手还在不断增加。每一批150秒,我正在处理3-5 k事件。我的问题是:-
- 这是一个有效的场景吗?
- 如果这不是一个有效的场景,那么原因可能是什么?是因为动态分配属性设置为true吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-10-27 12:58:55
是的,当启用动态分配时,这是一个有效的场景。
在结构化流中,数据以微批方式处理。如果执行器空闲超时时间小于微批处理持续时间,则会不断添加和删除执行程序。但是,如果执行器空闲超时时间大于批处理持续时间,则永远不会删除执行程序。控制此行为的属性为"spark.dynamicAllocation.executorIdleTimeout",,默认值为60秒。
因此,在60秒内,如果没有活动,执行者将被移除。在您的情况下,由于触发间隔为150秒,since会相当快地处理3-5k事件的小批处理,并且执行者有可能在超过60秒的时间内处于空闲状态,从而被移除。
若要更改此行为,请添加一个新的配置"spark.dynamicAllocation.executorIdleTimeout“并将其设置为更高的值(例如300秒)。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64549024
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号