
python中元素组合的计数频率
python中元素组合的计数频率
提问于 2020-11-03 09:08:50
我有以下df:
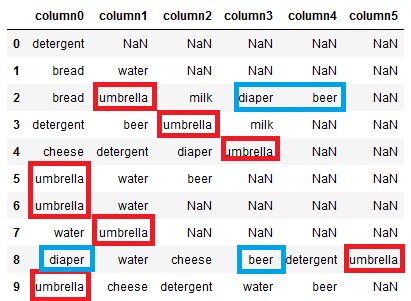
我想做的是数一数元素组合的频率。例如:
整个df times
- (umbrella,
- 雨伞出现8次
- 洗涤剂出现5次
- (啤酒尿布)出现2次
- (啤酒,牛奶)出现2次
- (啤酒)出现2次
F 212
以此类推,换句话说,我需要产生这样的东西:
计数单个项目和组合项的所有频率,并且只保留那些频率为>= n的单项和组合项,其中n是任何正整数。对于这个例子,让我们假设n -> {1,2,3,4}。
我一直试图使用以下代码:
# candidates itemsets
records = []
# generates a list of lists of products that were bought together (convert df to list of lists)
for i in range(0, num_records):
records.append([str(data.values[i,j]) for j in range(0, len(data.columns))])
# clean list (delete NaN values)
records = [[x for x in y if str(x) != 'nan'] for y in records]
OUTPUT:
[['detergent'],
['bread', 'water'],
['bread', 'umbrella', 'milk', 'diaper', 'beer'],
['detergent', 'beer', 'umbrella', 'milk'],
['cheese', 'detergent', 'diaper', 'umbrella'],
['umbrella', 'water', 'beer'],
['umbrella', 'water'],
['water', 'umbrella'],
['diaper', 'water', 'cheese', 'beer', 'detergent', 'umbrella'],
['umbrella', 'cheese', 'detergent', 'water', 'beer']]然后:
setOfItems = []
newListOfItems = []
for item in records:
if item in setOfItems:
continue
setOfItems.append(item)
temp = list(item)
occurence = records.count(item)
temp.append(occurence)
newListOfItems.append(temp)
OUTPUT:
['detergent', 1]
['bread', 'water', 1]
['bread', 'umbrella', 'milk', 'diaper', 'beer', 1]
['detergent', 'beer', 'umbrella', 'milk', 1]
['cheese', 'detergent', 'diaper', 'umbrella', 1]
['umbrella', 'water', 'beer', 1]
['umbrella', 'water', 1]
['water', 'umbrella', 1]
['diaper', 'water', 'cheese', 'beer', 'detergent', 'umbrella', 1]
['umbrella', 'cheese', 'detergent', 'water', 'beer', 1]正如您所看到的,它只是计算整个行的freq (从图1),但是我的预期输出是出现在第二个图像中的输出。
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-11-03 21:10:17
有趣的问题!我使用itertools.combinations()生成所有可能的组合,使用collections.Counter()来计算每一个组合出现的频率:
import pandas as pd
import itertools
from collections import Counter
# create sample data
df = pd.DataFrame([
['detergent', np.nan],
['bread', 'water', None],
['bread', 'umbrella', 'milk', 'diaper', 'beer'],
['umbrella', 'water'],
['water', 'umbrella'],
['umbrella', 'water']
])
def get_all_combinations_without_nan_or_None(row):
# remove nan, None and double values
set_without_nan = {value for value in row if isinstance(value, str)}
# generate all possible combinations of the values in a row
all_combinations = []
for i in range(1, len(set_without_nan)+1):
result = list(itertools.combinations(set_without_nan, i))
all_combinations.extend(result)
return all_combinations
# get all posssible combinations of values in a row
all_rows = df.apply(get_all_combinations_without_nan_or_None, 1).values
all_rows_flatten = list(itertools.chain.from_iterable(all_rows))
# use Counter to count how many there are of each combination
count_combinations = Counter(all_rows_flatten)collections.Counter()上的文档:
https://docs.python.org/2/library/collections.html#collections.Counter
itertools.combinations()上的文档:
https://docs.python.org/2/library/itertools.html#itertools.combinations
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64659769
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号