
随机森林图像中的决策树数和总颜色
随机森林图像中的决策树数和总颜色
提问于 2020-11-09 00:50:10
我正在训练一个随机森林模型,使用sklearn作为图像。我了解到,通过增加模型的深度,决策树可以扩展,可以包含更多的颜色。
不过,我不明白增加模型中的树数是如何影响色块数量的。我的印象是,树的数量被用来对值进行平均化,消除偏见--所以我的印象是,盒子的划分可能会改变,但颜色的总数量将保持不变(因为你仍然有相同的决策数量)。在运行1,3,5,10,100的树模型时,我确实看到,有100棵树的模型确实通过框的阴影有更多的颜色补丁。
有人能给我解释一下为什么增加树木的数量似乎会增加颜色斑块的数量吗?
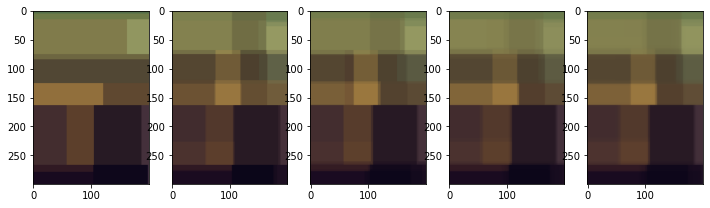
回答 1
Stack Overflow用户
回答已采纳
发布于 2020-11-09 01:52:28
它不会增加颜色补丁的数量。
想象一下,如果你只有两个色块,黑色和白色,但在你的森林中的50棵树。如果25/50的树预测黑色,而其他的预测是白色,你会给出一个点什么颜色?您可以简单地输出黑色或白色,但您也可以输出灰色作为一个更准确的可视化。
这就是你的视觉效果,原色保持不变,但是如果集合中的不同树预测不同,它们可以混合。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64744567
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号