
在DataFrame中的一个列包含另一个列的子字符串时,是否有一种方法只保留该数据帧中的行?
在DataFrame中的一个列包含另一个列的子字符串时,是否有一种方法只保留该数据帧中的行?
提问于 2020-11-10 12:09:25
我有一个数据集:
id key value
24 Apple Inc_Desktops revenue_rgs_category_-_pc_monitors nan
2 Apple Inc_Desktops revenue_rgs_category_-_mobile_phones 142381000000.000
46 Apple Inc_Desktops revenue_rgs_category_-_smart_tech 24482000000.000
13 Apple Inc_Desktops revenue_rgs_category_-_desktop_pcs 12870000000.000
35 Apple Inc_Desktops revenue_rgs_category_-_tablets 21280000000.000
1 Apple Inc_Laptops revenue_rgs_category_-_mobile_phones 142381000000.000
45 Apple Inc_Laptops revenue_rgs_category_-_smart_tech 24482000000.000
23 Apple Inc_Laptops revenue_rgs_category_-_pc_monitors nan
34 Apple Inc_Laptops revenue_rgs_category_-_tablets 21280000000.000
12 Apple Inc_Laptops revenue_rgs_category_-_desktop_pcs 12870000000.000
25 Apple Inc_MobilePhones revenue_rgs_category_-_pc_monitors nan
14 Apple Inc_MobilePhones revenue_rgs_category_-_desktop_pcs 12870000000.000
36 Apple Inc_MobilePhones revenue_rgs_category_-_tablets 21280000000.000
47 Apple Inc_MobilePhones revenue_rgs_category_-_smart_tech 24482000000.000
3 Apple Inc_MobilePhones revenue_rgs_category_-_mobile_phones 142381000000.000当列key包含来自id列的子字符串时,我只想保留行。例如,如下图所示,我只想保留索引13,3的行,因为对于那些行,'key‘列包含id列的一部分--例如,对于带有index 3的行,’index‘列包含在key列中。
所以我想要的输出是:
id key value
13 Apple Inc_Desktops revenue_rgs_category_-_desktop_pcs 12870000000.000
3 Apple Inc_MobilePhones revenue_rgs_category_-_mobile_phones 142381000000.000我尝试创建一个新的,指示'key‘列是否包含'id’列的子字符串,但运气不好:
comp_rev_long['check'] = comp_rev_long['key'].str.contains('|'.join(comp_rev_long['id']),case=False)有什么办法能有效地做到这一点吗?提前感谢你。
回答 2
Stack Overflow用户
回答已采纳
发布于 2020-11-10 14:11:19
下面是一些可以帮助您入门的代码:
import numpy as np
import pandas as pd
np.random.seed(1)
# I create a simple DataFrame
df = pd.DataFrame({"id": np.random.choice(["apple", "banana", "cherry"], 15),
"key": np.random.choice(["apple pie", "banana pie", "cherry pie"], 15),
"value": np.random.randint(0,20, 15)})df看起来是这样的:
id key value
0 banana cherry pie 13
1 apple banana pie 9
2 apple cherry pie 9
3 banana apple pie 7
4 banana apple pie 1
5 apple cherry pie 0
6 apple apple pie 17
7 banana banana pie 8
8 apple cherry pie 13
9 banana cherry pie 19
10 apple apple pie 15
11 cherry banana pie 10
12 banana banana pie 8
13 cherry cherry pie 7
14 apple apple pie 3这里有一个简单的选项,只选择满足特定条件的行。
# create a function that checks if a row satisfies your condition
check_condition = lambda row: row["id"] in row["key"]
# create a new column that determines whether you keep the row
# by applying the check_condition function row wise (-> axis=1)
df["keep_row"] = df.apply(check_condition, axis=1)
# finally select and keep only the desired rows
df = df[df["keep_row"]]现在,df看起来如下:
id key value keep_row
6 apple apple pie 17 True
7 banana banana pie 8 True
10 apple apple pie 15 True
12 banana banana pie 8 True
13 cherry cherry pie 7 True
14 apple apple pie 3 True最后一个问题是如何检查子字符串是否包含在另一个字符串中。有几种方法可以解决这个问题。
- 替换这些值,这样操作就变得琐碎了,例如。如果您只需要知道
row["id"] in row["key"] - Make是
mobile还是pc创建了一个新的“设备”列,那么 - 只是对其进行编码,尽管
有点麻烦。
这个check_condition可能会正常工作,可以查看您的数据,但我当然不能确定。
def check_condition(row):
for i in row["id"].lower().split('_'):
if i in row["key"].lower():
return True
elif i[:-1] in row["key"].lower(): # account for the final 's'
return True
return False2注:
- --这不是lambda函数,但在本例中它相当于一个函数,因此您可以用这个函数替换lambda
check_condition-function。 - 还注意到,在"id“和"key”列中,有些词以'-s‘结尾,而有些则不需要考虑。
Stack Overflow用户
发布于 2020-11-10 12:58:33
解决您的问题的一个解决方案是检查索引列中是否存在键列中的字符串。在下面的示例中,我构造了一个df (因为您没有提供一个df,其中一个列中包含字符串,另一个列中包含字符串):
import pandas as pd
a1,b2,c3 = 'ANDGFEEHsdsdSHSHS','FKDsdsdKSDKSDKS','DSLDJSLffsfsKDdSLDJS'
s1, s2, s3 = 1,3,1
e1, e2, e3 = 3,6,6
df = pd.DataFrame({'key':[a1,b2,c3],'start': [s1, s2, s3],'end': [e1, e2, e3]})
df = df[['key', 'start', 'end']]
df['sliced'] = df.apply(fn, axis = 1)
aa1,bb2,cc3 = 'ANDGFEEHsdsdSHSHS','FKDsdsdKSDKSDKS','DSLDJSLffsfsKDdSLDJS'
ss1, ss2, ss3 = 2,2,2
ee1, ee2, ee3 = 1,1,1
df2 = pd.DataFrame({'key':[aa1,bb2,cc3],'start': [ss1, ss2, ss3],'end': [ee1, ee2, ee3]})
df2 = df2[['key', 'start', 'end']]
dff = df.append(df2)
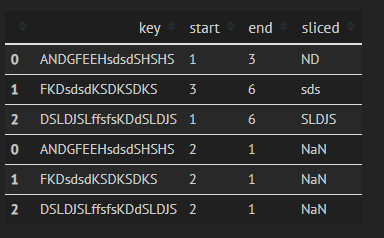
将此应用于确定key中是否存在一个列中的字符串。
df['Check'] = df.apply(lambda x: x.sliced in x.key, axis=1)
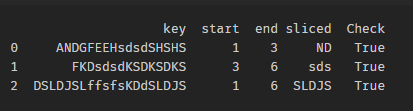
并为True切片。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64768674
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号