
熊猫阅读IRS空间分隔的txt数据
熊猫阅读IRS空间分隔的txt数据
提问于 2020-11-14 03:22:07
我最近在处理国税局的税务档案数据。它是以空格分隔的txt数据,如下所示(完整数据为这里):
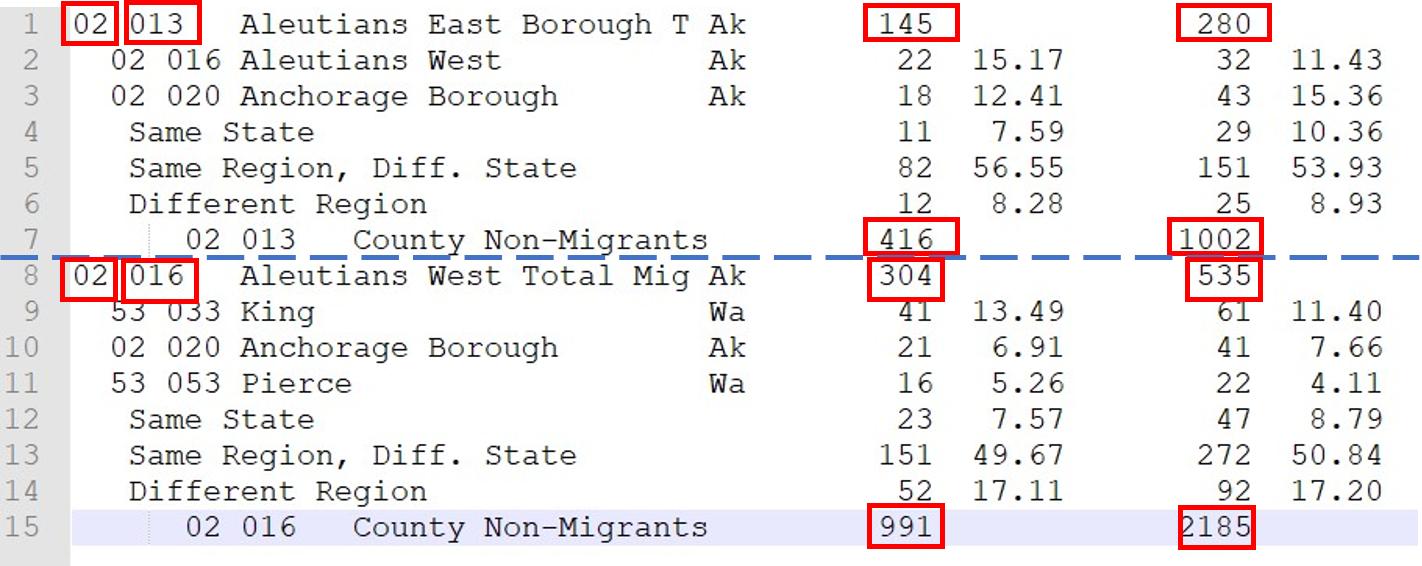
数据的存储方式有一些模式。但是对我来说,数据不是以标准的方式格式化的,也不容易读到Pandas。我想知道如何从上面的txt数据中获得如下数据:
+------------+-------------+--------------------------+-----+-----+-----+------+
| fips_state | fips_county | name | c1 | c2 | c3 | c4 |
+------------+-------------+--------------------------+-----+-----+-----+------+
| 02 | 013 | Aleutians East Borough T | 145 | 280 | 416 | 1002 |
| 02 | 016 | Aleutians West Total Mig | 304 | 535 | 991 | 2185 |
| ... | ... | ... | ... | ... | ... | ... |
+------------+-------------+--------------------------+-----+-----+-----+------+回答 1
Stack Overflow用户
回答已采纳
发布于 2020-11-14 17:26:51
这将使您在熊猫内或在创建列表之前,将数据放入两个单独的数据栏中。解析后,合并两个数据文件。
import urllib.request # the lib that handles the url stuff
target_url='https://raw.githubusercontent.com/shuai-zhou/DataRepo/master/data/C9091aki.txt'
list_a = []
list_b = []
for line in urllib.request.urlopen(target_url):
if line.decode('utf-8')[0:2] != ' ':
print(line.decode('utf-8').strip())
list_a.append(line.decode('utf-8').strip())
if line.decode('utf-8')[0:5] == ' ':
print(line.decode('utf-8').strip())
list_b.append(line.decode('utf-8').strip())
dfa = pd.DataFrame(list_a)
dfb = pd.DataFrame(list_b)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/64830630
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号